>>> help(input) Help on built-in function input in module builtins:
input(prompt=None, /) Read a string from standard input. The trailing newline is stripped. The prompt string, if given, is printed to standard output without a trailing newline before reading input. If the user hits EOF (*nix: Ctrl-D, Windows: Ctrl-Z+Return), raise EOFError. On *nix systems, readline is used if available.
eval() 去掉变量的引号
1 2 3 4 5 6 7 8 9 10 11 12 13
>>> help(eval) Help on built-in function eval in module builtins:
eval(source, globals=None, locals=None, /) Evaluate the given source in the context of globals and locals. The source may be a string representing a Python expression or a code object as returned by compile(). The globals must be a dictionary and locals can be any mapping, defaulting to the current globals and locals. If only globals is given, locals defaults to it.
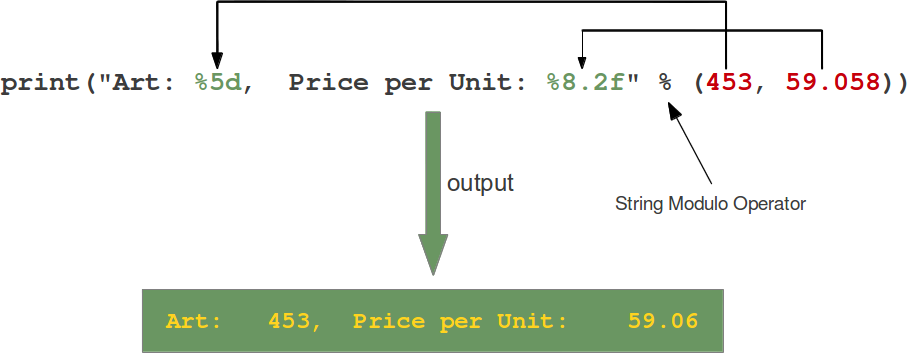
print 函数
1 2 3 4 5 6 7 8 9 10 11 12
>>> help(print) Help on built-in function printin module builtins:
print(...) print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) Prints the values to a stream, or to sys.stdout by default. Optional keyword arguments: file: a file-like object (stream); defaults to the current sys.stdout. sep: string inserted between values, default a space. end: string appended after the last value, default a newline. flush: whether to forcibly flush the stream.
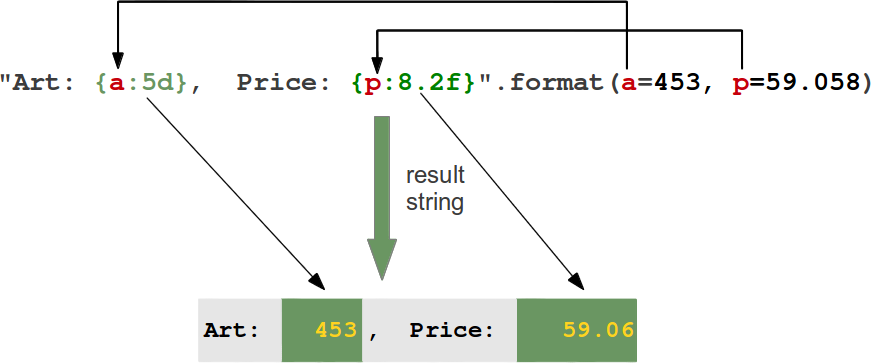
>>> help(format) >>> help(str.format) Help on method_descriptor:
format(...) S.format(*args, **kwargs) -> str Return a formatted version of S, using substitutions from args and kwargs. The substitutions are identified by braces ('{'and'}').
程序的控制结构
分支结构
if if … :
....
if-else: if … :
....
else:
...
也可以写在一行里: <expression1> if <condition> else <expression2>
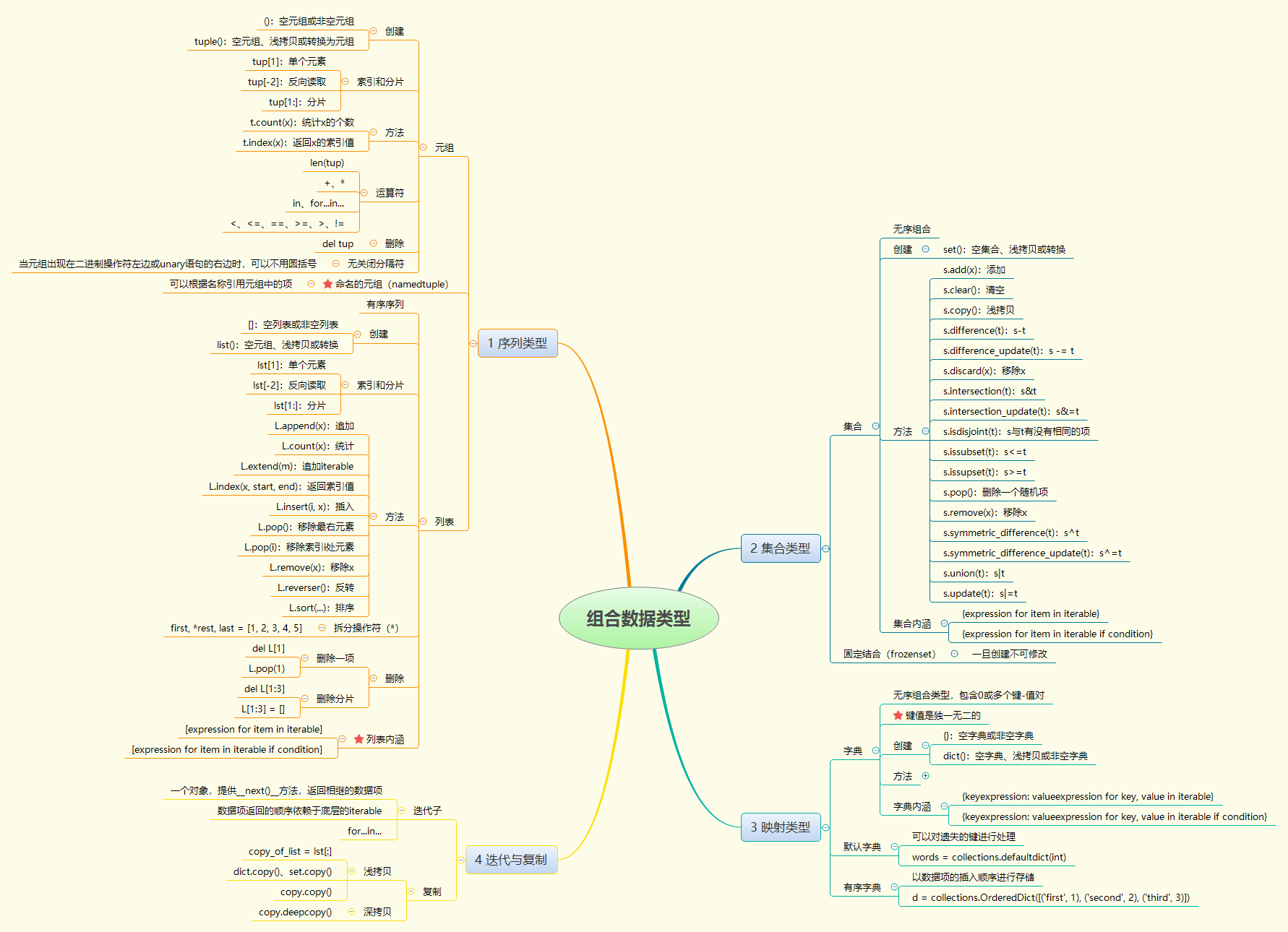
S.add(x) S.clear() S.copy() S.pop() 随机返回S中的一个元素 S.discard(x) 如果x在S中,移除x,不在的话没关系 S.remove(x) S.isdisjoint(T) 返回 TrueFalse 如果X和T没有相同的元素则True len(S) x in S x notin S
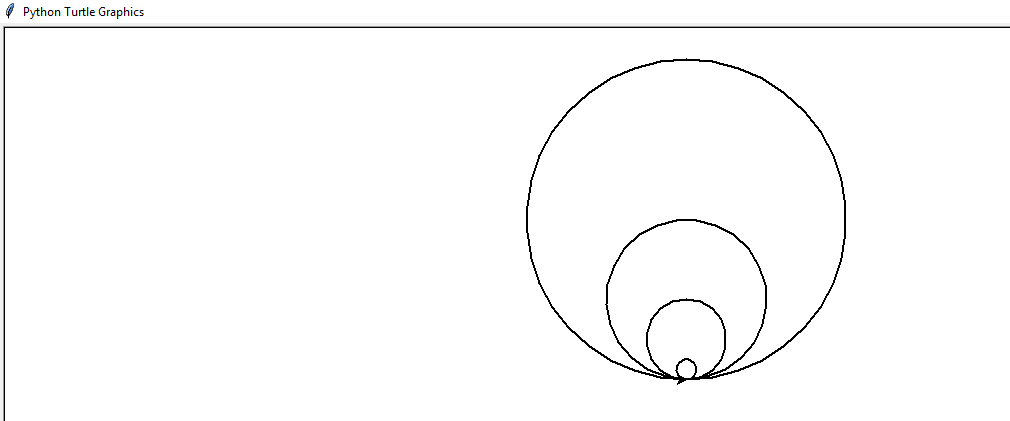
for i in range(4): turtle.circle(40,80) turtle.circle(-40,80) #turtle.circle(radius,extent=none) 用来绘制一个弧形,none的话为整个圆。 #(半径,扇形的角度)正值与负值的区别。。。 turtle.circle(40,80/2) turtle.fd(40) turtle.circle(16,180) turtle.fd(40*2/3)
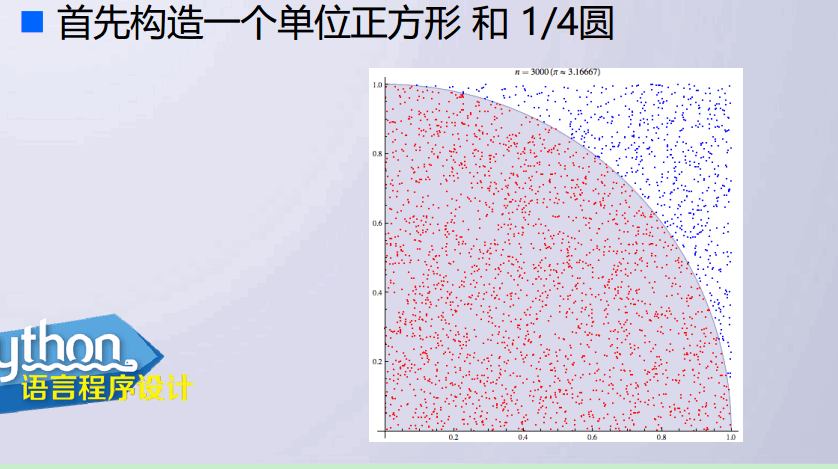
from random import random from math import sqrt from time import clock DARTS=10000 hits=0.0 clock() for i in range(1,DARTS+1): x,y=random(),random() dist=sqrt(x**2+y**2) if dist<=1.0: hits=hits+1 pi=4*(hits/DARTS) print("pi值是{}.".format(pi)) print("运行时间是:{:8.7}s".format(clock()))
结果:
1 2 3 4 5 6 7 8 9 10 11 12
Warning (from warnings module): File "F:/U/software/py/a2.py", line 6 clock() DeprecationWarning: time.clock has been deprecated in Python 3.3and will be removed from Python 3.8: use time.perf_counter or time.process_time instead pi值是3.1432.
Warning (from warnings module): File "F:/U/software/py/a2.py", line 14 print("运行时间是:{:8.7}s".format(clock())) DeprecationWarning: time.clock has been deprecated in Python 3.3and will be removed from Python 3.8: use time.perf_counter or time.process_time instead 运行时间是:0.5633718s
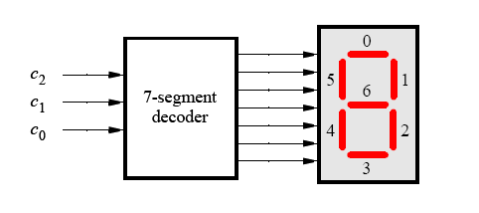
import turtle,datetime defdrawLine(draw):#一笔管 turtle.pendown() if draw else turtle.penup() turtle.fd(40) turtle.right(90)
defdrawDigit(d): drawLine(True) if d in [2,3,4,5,6,8,9] else drawLine(False) #第一笔 drawLine(True) if d in [0,1,3,4,5,6,7,8,9] else drawLine(False) drawLine(True) if d in [0,2,3,5,6,8,9] else drawLine(False) drawLine(True) if d in [0,2,6,8] else drawLine(False) turtle.left(90)#往左转回去的意思!!! drawLine(True) if d in [0,4,5,6,8,9] else drawLine(False) drawLine(True) if d in [0,2,3,4,5,6,8,9] else drawLine(False) drawLine(True) if d in [0,1,2,3,4,7,8,9] else drawLine(False)
turtle.left(180) turtle.penup() turtle.fd(20)
defdrawDate(date): for i in date: drawDigit(eval(i))
defdrawLine(draw):#一笔管 drawGap() turtle.pendown() if draw else turtle.penup() turtle.fd(40) drawGap() turtle.right(90)
defdrawDigit(d): drawLine(True) if d in [2,3,4,5,6,8,9] else drawLine(False) #第一笔 drawLine(True) if d in [0,1,3,4,5,6,7,8,9] else drawLine(False) drawLine(True) if d in [0,2,3,5,6,8,9] else drawLine(False) drawLine(True) if d in [0,2,6,8] else drawLine(False) turtle.left(90)#往左转回去的意思!!! drawLine(True) if d in [0,4,5,6,8,9] else drawLine(False) drawLine(True) if d in [0,2,3,4,5,6,8,9] else drawLine(False) drawLine(True) if d in [0,1,2,3,4,7,8,9] else drawLine(False)
turtle.left(180) turtle.penup() turtle.fd(20)
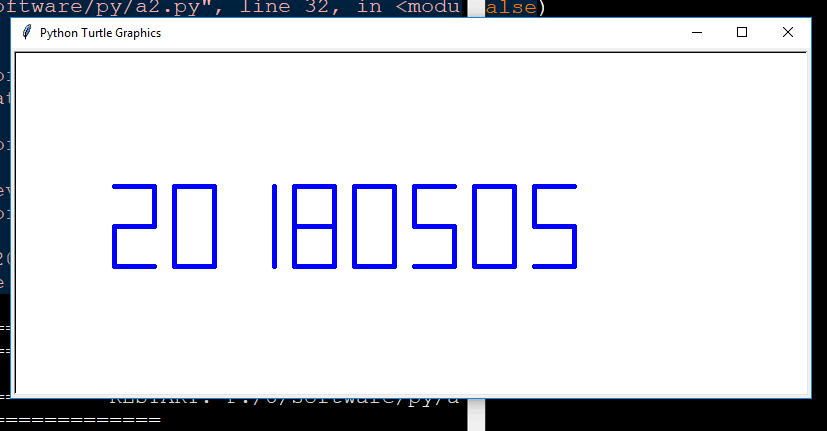
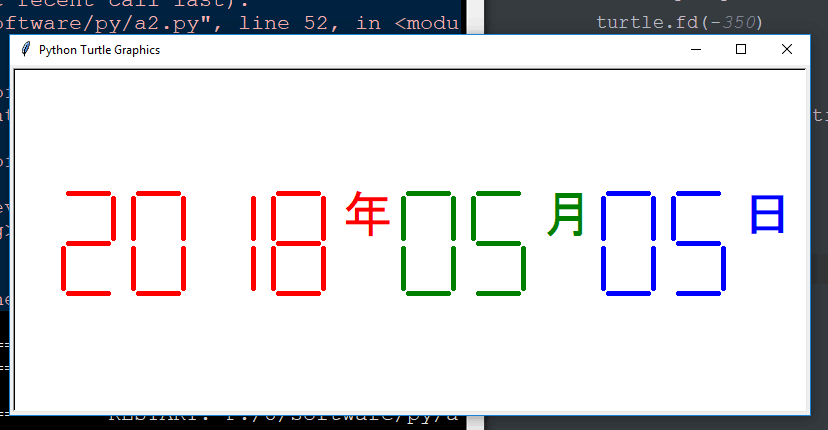
defdrawDate(date): turtle.pencolor('red') for i in date: if i== '-': turtle.write('年',font=("Arial",18,"normal")) turtle.pencolor('green') turtle.fd(40) if i== '=': turtle.write('月',font=("Arial",18,"normal")) turtle.pencolor('blue') turtle.fd(40) if i== '+': turtle.write('日',font=("Arial",18,"normal")) else: drawDigit(eval(i))
Traceback (most recent call last): File "F:/U/software/py/a2.py", line 52, in <module> main() File "F:/U/software/py/a2.py", line 50, in main drawDate(datetime.datetime.now().strftime('%Y-%m=%d+')) File "F:/U/software/py/a2.py", line 42, in drawDate drawDigit(eval(i)) File "<string>", line 1 - ^ SyntaxError: unexpected EOF while parsing >>>
#e7.2DrawSevenSegDisplay.py import turtle, datetime defdrawGap():#绘制数码管间隔 turtle.penup() turtle.fd(5) defdrawLine(draw):#绘制单段数码管 drawGap() turtle.pendown() if draw else turtle.penup() turtle.fd(40) drawGap() turtle.right(90) defdrawDigit(d):#根据数字绘制七段数码管 drawLine(True) if d in [2,3,4,5,6,8,9] else drawLine(False) drawLine(True) if d in [0,1,3,4,5,6,7,8,9] else drawLine(False) drawLine(True) if d in [0,2,3,5,6,8,9] else drawLine(False) drawLine(True) if d in [0,2,6,8] else drawLine(False) turtle.left(90) drawLine(True) if d in [0,4,5,6,8,9] else drawLine(False) drawLine(True) if d in [0,2,3,5,6,7,8,9] else drawLine(False) drawLine(True) if d in [0,1,2,3,4,7,8,9] else drawLine(False) turtle.left(180) turtle.penup() turtle.fd(20) defdrawDate(date): turtle.pencolor("red") for i in date: if i == '-': turtle.write('年',font=("Arial", 18, "normal")) turtle.pencolor("green") turtle.fd(40) elif i == '=': turtle.write('月',font=("Arial", 18, "normal")) turtle.pencolor("blue") turtle.fd(40) elif i == '+': turtle.write('日',font=("Arial", 18, "normal")) else: drawDigit(eval(i)) defmain(): turtle.setup(800, 350, 200, 200) turtle.penup() turtle.fd(-350) turtle.pensize(5) drawDate(datetime.datetime.now().strftime('%Y-%m=%d+')) turtle.hideturtle() main()
递归
n的阶乘:
1 2 3 4 5 6 7
deffact(n): if n==0: return1 else: return n*fact(n-1) num=eval(input("请输入一个整数: ")) print(fact(abs(int(num))))
主要是return语句的使用。。。 当然也可以没有return语句。。
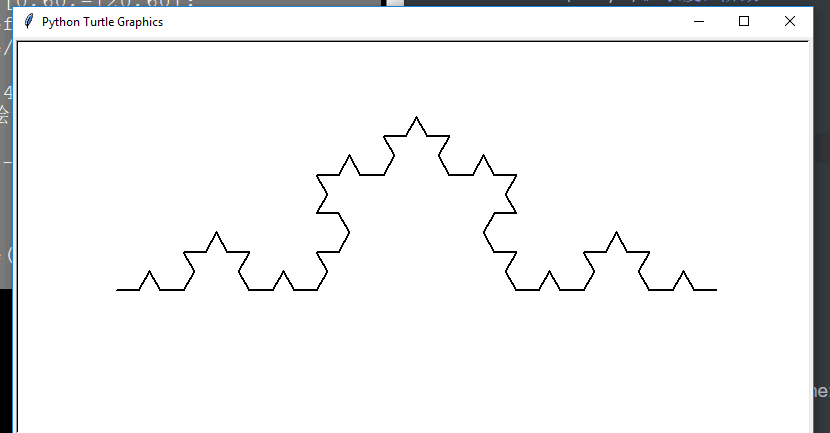
科赫曲线
n阶科赫曲线
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import turtle defkoch(size,n): if n==0: turtle.fd(size) else: for angle in [0,60,-120,60]: turtle.left(angle) koch(size/3,n-1) defmain(): turtle.setup(800,400) turtle.speed(0)#绘制速度 turtle.penup() turtle.goto(-300,-50) turtle.pendown() turtle.pensize(2) koch(600,3)# 长度,阶数 turtle.hideturtle() main()
>>> help(datetime) Help on classdatetimeinmoduledatetime:
classdatetime(date) | datetime(year, month, day[, hour[, minute[, second[, microsecond[,tzinfo]]]]]) | | The year, month and day arguments are required. tzinfo may be None, or an | instance of a tzinfo subclass. The remaining arguments may be ints. | | Method resolution order: | datetime | date | builtins.object | | Methods defined here: | | __add__(self, value, /) | Return self+value. | | __eq__(self, value, /) | Return self==value. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __gt__(self, value, /) | Return self>value. | | __hash__(self, /) | Return hash(self). | | __le__(self, value, /) | Return self<=value. | | __lt__(self, value, /) | Return self<value. | | __ne__(self, value, /) | Return self!=value. | | __radd__(self, value, /) | Return value+self. | | __reduce__(...) | __reduce__() -> (cls, state) | | __reduce_ex__(...) | __reduce_ex__(proto) -> (cls, state) | | __repr__(self, /) | Return repr(self). | | __rsub__(self, value, /) | Return value-self. | | __str__(self, /) | Return str(self). | | __sub__(self, value, /) | Return self-value. | | astimezone(...) | tz -> convert to local time in new timezone tz | | ctime(...) | Return ctime() style string. | | date(...) | Return date object with same year, month and day. | | dst(...) | Return self.tzinfo.dst(self). | | isoformat(...) | [sep] -> string in ISO 8601 format, YYYY-MM-DDT[HH[:MM[:SS[.mmm[uuu]]]]][+HH:MM]. | sep is used to separate the year from the time, and defaults to 'T'. | timespec specifies what components of the time to include (allowed values are 'auto', 'hours', 'minutes', 'seconds', 'milliseconds', and'microseconds'). | | replace(...) | Return datetime with new specified fields. | | time(...) | Return time object with same time but with tzinfo=None. | | timestamp(...) | Return POSIX timestamp as float. | | timetuple(...) | Return time tuple, compatible with time.localtime(). | | timetz(...) | Return time object with same time and tzinfo. | | tzname(...) | Return self.tzinfo.tzname(self). | | utcoffset(...) | Return self.tzinfo.utcoffset(self). | | utctimetuple(...) | Return UTC time tuple, compatible with time.localtime(). | | ---------------------------------------------------------------------- | Class methods defined here: | | combine(...) from builtins.type | date, time -> datetime with same date and time fields | | fromisoformat(...) from builtins.type | string -> datetime from datetime.isoformat() output | | fromtimestamp(...) from builtins.type | timestamp[, tz] -> tz's local time from POSIX timestamp. | | now(tz=None) from builtins.type | Returns new datetime object representing current time local to tz. | | tz | Timezone object. | | If no tz is specified, uses local timezone. | | strptime(...) from builtins.type | string, format -> new datetime parsed from a string (like time.strptime()). | | utcfromtimestamp(...) from builtins.type | Construct a naive UTC datetime from a POSIX timestamp. | | utcnow(...) from builtins.type | Return a new datetime representing UTC day and time. | | ---------------------------------------------------------------------- | Static methods defined here: | | __new__(*args, **kwargs) from builtins.type | Create andreturn a new object. See help(type) for accurate signature. | | ---------------------------------------------------------------------- | Data descriptors defined here: | | fold | | hour | | microsecond | | minute | | second | | tzinfo | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | max = datetime.datetime(9999, 12, 31, 23, 59, 59, 999999) | | min = datetime.datetime(1, 1, 1, 0, 0) | | resolution = datetime.timedelta(microseconds=1) | | ---------------------------------------------------------------------- | Methods inherited from date: | | __format__(...) | Formats self with strftime. | | isocalendar(...) | Return a 3-tuple containing ISO year, week number, and weekday. | | isoweekday(...) | Return the day of the week represented by the date. | Monday == 1 ... Sunday == 7 | | strftime(...) | format -> strftime() style string. | | toordinal(...) | Return proleptic Gregorian ordinal. January 1 of year 1is day 1. | | weekday(...) | Return the day of the week represented by the date. | Monday == 0 ... Sunday == 6 | | ---------------------------------------------------------------------- | Class methods inherited from date: | | fromordinal(...) from builtins.type | int -> date corresponding to a proleptic Gregorian ordinal. | | today(...) from builtins.type | Current date or datetime: same as self.__class__.fromtimestamp(time.time()). | | ---------------------------------------------------------------------- | Data descriptors inherited from date: | | day | | month | | year
>>>
jieba库
第三方中文分词函数库 把一大段话分解为一个个词或字
使用pip工具安装 pip install jieba
结巴库分三种模式:
精确模式 精确的分开
全模式 速度块
搜索引擎模式 在精确的模式上再次切分
常用分词函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14
jieba.cut(s) 精确模式,返回一个迭代类型
jieba.cut(s,cut_all=True) 全模式
jieba.cut_for_search(s) 搜索引擎模式
jieba.lcut(s) 精确模式,但是返回列表类型
jieba.lcut(s,cut_all=Ture) 全模式,返回列表
jieba.lcut_for_search(s) 搜索引擎模式,返回一个列表
jieba.add_word(w) 向分词词典中增加一个新词 w
文本词频统计
英文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#cal hamlet numbers
defgetText(): txt=open("ss.txt","r",encoding='utf-8').read() txt=txt.lower() for ch in'!"#$%&*()+_-,.-/:;<=>?@[\\]^`~': txt=txt.replace(ch," ") return txt hamletTxt=getText() words=hamletTxt.split() counts = {} for word in words: counts[word]=counts.get(word,0)+1 items =list(counts.items()) items.sort(key=lambda x:x[1],reverse=True)#匿名函数,key:排序方式,reverse:是否反序 for i in range (10): word,count=items[i] print("{0:<10}{1:>5}".format(word,count))
1 2 3 4 5 6 7 8 9 10 11 12 13
>>> ====================== RESTART: F:/U/software/py/a2.py ====================== the 1137 and965 to 754 of 667 you 550 a 542 i 541 my 514 hamlet 461 in436 >>>
#e10.4CalThreeKingdoms.py import jieba excludes = {"将军","却说","荆州","二人","不可","不能","如此"} txt = open("三国演义.txt", "r", encoding='utf-8').read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue elif word == "诸葛亮"or word == "孔明曰": rword = "孔明" elif word == "关公"or word == "云长": rword = "关羽" elif word == "玄德"or word == "玄德曰": rword = "刘备" elif word == "孟德"or word == "丞相": rword = "曹操" else: rword = word counts[rword] = counts.get(rword,0) + 1 for word in excludes: del(counts[word]) items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(5): word, count = items[i] print ("{0:<10}{1:>5}".format(word, count))