大数据
初识大数据
Hadoop
http://dblab.xmu.edu.cn/blog/285/
大数据概述
三次信息化浪潮
根据IBM前首席执行官郭士纳的观点, IT领域每隔十五年就会迎来一次重大变革 :
| 信息化浪潮 | 发生时间 | 标志 | 解决问题 | 代表企业 |
|---|---|---|---|---|
| 第一次浪潮 | 1980年前后 | 个人计算机 | 信息处理 | Intel、 AMD、 IBM、苹 果、微软、联想、戴 尔、惠普等 |
| 第二次浪潮 | 1995年前后 | 互联网 | 信息传输 | 雅虎、谷歌、阿里巴 巴、百度、腾讯等 |
| 第三次浪潮 | 2010年前后 | 物联网、云计 算和大数据 | 信息爆炸 | 将涌现出一批新的市 场标杆企业 |
存储
数据存储:压缩
来自斯威本科技大学(Swinburne University of Technology)的研究团队,在2013年6月29日刊出的《自然通讯(Nature Communications) 》 杂志的文章中,描述了一种全新的数据存储方式,可1PB(1024TB)的数据存储到一张仅DVD大小的聚合、物碟片上。
cpu中晶体管数量
RFID
感知使系统。
大数据发展历程
| 阶段 | 时间 | 内容 |
|---|---|---|
| 第一阶段:萌芽 期 | 上世纪90年代 至本世纪初 | 随着数据挖掘理论和数据库技术的逐步成熟,一批 商业智能工具和知识管理技术开始被应用,如数据 仓库、专家系统、知识管理系统等。 |
| 第二阶段:成熟 期 | 本世纪前十年 | Web2.0应用迅猛发展,非结构化数据大量产生, 传统处理方法难以应对,带动了大数据技术的快速 突破,大数据解决方案逐渐走向成熟,形成了并行 计算与分布式系统两大核心技术,谷歌的GFS和 MapReduce等大数据技术受到追捧, Hadoop平台 开始大行其道 |
| 第三阶段:大规 模应用期 | 2010年以后 | 大数据应用渗透各行各业,数据驱动决策,信息社 会智能化程度大幅提高 |
4V
- 数据量大 volume
- 数据类型多 variety
大数据是由结构化和非结构化数据组成的
– 10%的结构化数据,存储在数据库中
– 90%的非结构化数据,它们与人类信息密切相关
- 处理速度快 velocity
1秒定律
- value 价值密度低
以视频为例,连续不间断监控过程中,可能有用的数据仅仅有一两秒,但是具有很高的商业价值
大数据影响
图灵奖获得者、著名数据库专家Jim Gray 博士观察并总结人类自古以来,在科学研究上,先后历经了实验、理论、计算和数据四种范式
大数据技术
大数据技术的不同层面及其功能
| 技术层面 | 功能 |
|---|---|
| 数据采集 | 利用ETL工具将分布的、异构数据源中的数据如关系数据、平面数 据文件等,抽取到临时中间层后进行清洗、转换、集成,最后加载 到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础; 或者也可以把实时采集的数据作为流计算系统的输入,进行实时处 理分析 |
| 数据存储和管理 | 利用分布式文件系统、数据仓库、关系数据库、 NoSQL数据库、云 数据库等,实现对结构化、半结构化和非结构化海量数据的存储和 管理 |
| 数据处理与分析 | 利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算 法,实现对海量数据的处理和分析;对分析结果进行可视化呈现, 帮助人们更好地理解数据、分析数据 |
| 数据隐私和安全 | 在从大数据中挖掘潜在的巨大商业价值和学术价值的同时,构建隐 私数据保护体系和数据安全体系,有效保护个人隐私和数据安全 |
两大关键技术
分布式存储
分布式处理
计算模式
| 大数据计算模式 | 解决问题 | 代表产品 |
|---|---|---|
| 批处理计算 | 针对大规模数据的批量 处理 | MapReduce、 Spark等 |
| 流计算 | 针对流数据的实时计算 | Storm、 S4、 Flume、 Streams、 Puma、 DStream、 Super Mario、银 河流数据处理平台等 |
| 图计算 | 针对大规模图结构数据 的处理 | Pregel、 GraphX、 Giraph、 PowerGraph、 Hama、 GoldenOrb等 |
| 查询分析计算 | 大规模数据的存储管理 和查询分析 | Dremel、 Hive、 Cassandra、 Impala 等 |
大数据,云计算,物联网
云计算
• 云计算实现了通过网络提供可伸缩的、廉价的分布式计算能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源
SaaS Software as a Service Google Apps, Microsoft “Software+Services”
PaaS Platform as a Service IBM IT factory, Google App Engine, Force.com
IaaS Infrastructure as a Service Amazon EC2, IBM Blue Cloud, Sun Grid
云计算关键技术包括:虚拟化、分布式存储、分布式计算、多租户等
云计算数据中心
复杂,刀片服务器,温度
物联网
关键技术包括识别和感知技术(二维码、 RFID、传感器等)、网络与通信技术、数据挖掘与融合技术等 rfid芯片公交卡
总结
云计算为大数据提供了技术基础
大数据为云计算提供用武之地
物联网是大数据的重要来源
大数据技术为物联网数据分析提供支撑
云计算为物联网提供海量数据存储能力
物联网为云计算技术提供了广阔的应用空间
初识hadoop
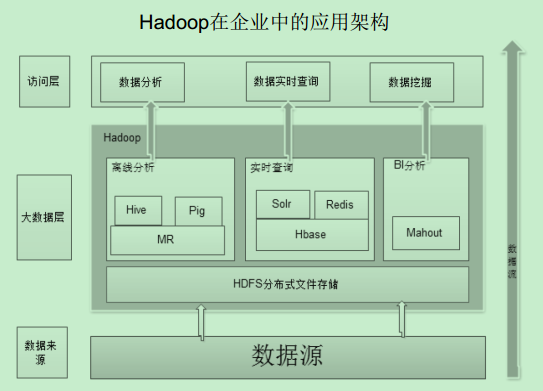
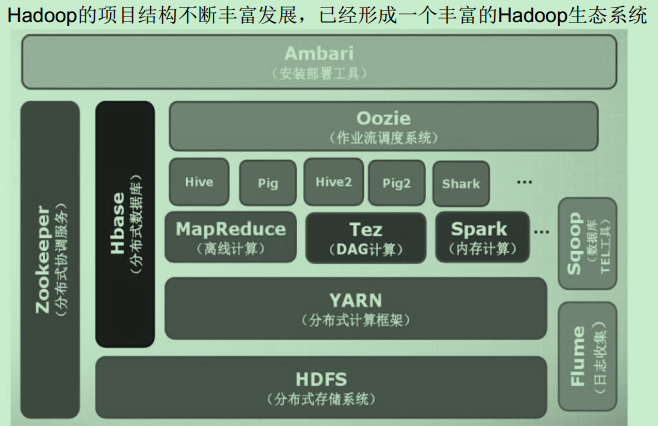
Hadoop项目结构 :
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |
• Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
• Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
• Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce
• Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力
• 几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop
NDFS(Nutch Distributed File System),也就是HDFS的前身
• 2004年,谷歌公司又发表了另一篇具有深远影响的论文,阐述了MapReduce分布式编程思想
• 2005年, Nutch开源实现了谷歌的MapReduce
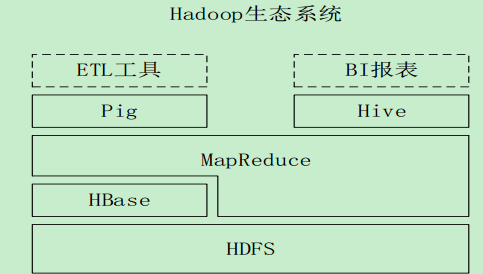
可查看hadoop的生态系统图!!
Hadoop安装方式
下载hadoop: xxx.tar.gz
1 |
|
/usr/local目录:
http://www.ruanyifeng.com/blog/2012/02/a_history_of_unix_directory_structure.html
/usr/local/ 存放用户自己安装的程序。
/opt:在某些系统,用于存放第三方厂商开发的程序,所以取名为option,意为”选装”。
《Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04》
http://dblab.xmu.edu.cn/blog/install-hadoop/
访问地址:http://dblab.xmu.edu.cn/blog/285/
hadoop学习指南:http://dblab.xmu.edu.cn/blog/285/
创建hadoop用户
添加相应的权限:
1 |
|
hadoop版本问题:
SSH登录权限设置
配置ssh,可实现其它机器无密码登陆。
hadoop的名称节点负责启动集群中的所有节点,名称节点需要登陆其他机器,hadoop没有密码登陆其他机器的功能,所以需要无密码登陆。
Secure Shell 的缩写:
一个安全协议,建立在应用层和传输层。
一般用于 远程登陆会话。一种安全性协议。
最初是unix上的一个程序。
ssh由客户端与服务端两个组成。
服务端是一个守护进程(daemon),在后端运行,负责接受客户端的请求。
客户端除了ssh本身,还像scp(远程拷贝)、slogin(远程登陆)、sftp(安全文件传输)等其他的应用程序。
配置SSH的原因:
Hadoop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护进程,这个过程需要通过SSH登录来实现。 Hadoop并没有提供SSH输入密码登录的形式,因此,为了能够顺利登录每台机器,需要将所有机器配置为名称节点可以无密码登录它们
安装java开发环境
配置hadoop
三种安装方式:
这三种方式的配置有区别!!!
《Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04》
http://dblab.xmu.edu.cn/blog/install-hadoop/
单机模式:
伪分布式模式:
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是HDFS 中的文件.
我目前学习的就是这种!
修改两个文件:
/usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml
xml 格式,每个配置以声明 property 的 name和 value 的方式来实现
1 |
|
1 |
|
三种shell命令方式的区别: 本地文件系统与hdfs文件系统的区别。
- hadoop fs 适用不同的文件系统
- hadoop dfs 只适用与hdfs文件系统
- hdfs dfs 同上
hadoop 集群中的节点类型
Hadoop框架中最核心的设计是为海量数据提供存储的HDFS和对数据进行计算的 MapReduce
MapReduce的作业主要包括:
(1)从磁盘或从网络读取数据,即IO密集工作;
(2)计算数据,即CPU密集工作
一个基本的Hadoop集群中的节点主要有
•NameNode:负责协调集群中的数据存储
•DataNode:存储被拆分的数据块
•JobTracker:协调数据计算任务
•TaskTracker:负责执行由JobTracker指派的任务
•SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
Hadoop 企业去部署它
MapReduce有两大核心组件。处理作业
JobTracker:相当于一个作业管家,一个大作业拆分为一个个小的作业,分发到不同的机器去处理。
TaskTracker:不同的机器上都有一个,负责跟踪和执行分配给自己的小作业。
HDFS的组件,SecondNameNode在1.0版本中不是热备份。
一个机器节点可以是TaskTracker也可以是DataNode.
现在问题来啦,怎么选硬件呢??
NameNode的数据大部分都是存储在内存当中的。所以内存要特别大。16~72G,内存要进行通道优化
集群可能有几千台,以T增加,还有日志文件,在大集群里,NameNode 与JobTracker一般是两个机器。
自动化部署工具,然后测试,HDFS与MapReduce
在云计算部署,
集群部署
Amazon EC2运行hadoop。弹性云
HDFS
分布式文件系统:(Distributed File System):把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群 .
目前的分布式文件系统所采用的计算机集群,都是由普通硬件构成的,这就大大降低了硬件上的开销 .
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点” (Master Node)或者也被称为“名称结点” (NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点” (DataNode)
hdfs:(hadoop distributed file system)
目的:
●兼容廉价的硬件设备
●流数据读写
●大数据集
●简单的文件模型,只允许追加,不允许修改
●强大的跨平台兼容性
缺陷:
●不适合低延迟数据访问
●无法高效存储大量小文件
●不支持多用户写入及任意修改文件
HDFS相关概念:
关键词: 块,名称节点,数据节点,第二名称节点
块:
为提高磁盘读写效率,不以字节为单位。 默认大小是64MB。
一个文件可以被分为许多的块,以块为存储单位,例如机械硬盘寻找数据时,可以最小化寻址开销。
每个块可以冗余存储到多个节点上。
可以分离出元数据来放到不同的文件系统上。
名称节点与数据节点
名称节点:NameNode
负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog .
- FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据 ,也就是数据在哪里
- 操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作 .
FsImage文件:包含文件系统中所有目录和文件inode的序列化形式。
每个inode是一个文件或目录的元数据的内部表示,并包含此类信息: 文件的复制等级、修改和访问
修改和访问时间、访问权限、块大小以及组成文件的块。对于目录,则存储修改时间、权限和配额元数据FsImage文件没有记录块存储在哪个数据节点。即不持久化存储这些信息,在系统启动时扫描所有数据节点重构得到这些信息。
由名称节点把这些映射保留在内存中,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。 是在内存中
名称节点的启动:如何处理这两大数据结构的
shell命令 在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数
据支持客户端的读操作。
一旦在内存中成功建立文件系统元数据的映射,**则创建一个新的FsImage文件和一个空的EditLog文件**
名称节点起来之后, HDFS中的更新操作会重新写到EditLog文件中,因为FsImage文件一般都很大(GB级别的很常见), 如果所有的更新操作都往FsImage文件中添加,这样会导致系统运行的十分缓慢, 但是,如果往EditLog文件里面写就不会这样,因为EditLog 要小很多**。每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新
名称节点运行期间EditLog不断变大的问题 :
在名称节点运行期间, HDFS的所有更新操作都是直接写到EditLog中,久而久之, EditLog文件将会变得很大 .
当名称节点重启的时候,名称节点需要先将FsImage里面的所有内容映像到内存中,然后再一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,会导致名称节点启动操作非常慢,而在这段时间内HDFS系统处于安全模式,一直无法对外提供写操作,影响了用户的使用 .解决方法是使用第二名称节点:
第二名称节点:是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元 数据信息的备份,并减少名称节点重启的时间。 SecondaryNameNode一般是单独运行在一台机器 。
SecondaryNameNode的工作情况:
(1) SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的 写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2) SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
(3) SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和 FsImage文件合并;
(4) SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
(5) NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了
数据节点:(DataNode)
•数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客 户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己 所存储的块的列表
每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
HDFS 体系结构
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode) 。
有图:HDFS体系结构。
命名空间管理(NameNode)
• 在HDFS1.0体系结构中, 在整个HDFS集群中只有一个命名空间, 并且只有唯一一个名称节点, 该节点负责对这个命名空间进行管理
命名空间管理:支持对HDFS中的目录,文件,和块做 创建,修改,删除等操作。
通信协议
数据通过网络进行传输。 而传输就就需要传输协议,HDFS都是构建在TCP/IP协议基础之上的。
• 客户端通过一个可配置的端口向名称节点主动发起TCP连接, 并使用客户端协议与名称节点进行交互
• 名称节点和数据节点之间则使用数据节点协议进行交互
• 客户端与数据节点的交互是通过RPC(Remote Procedure Call) 来实现的。 在设计上, 名称节点不会主动发起RPC, 而是响应来自客户端和数据节点的RPC请求
客户端
HDFS客户端是一个库, 暴露了HDFS文件系统接口, 这些接口隐藏了HDFS实现中的大部分复杂性
• 严格来说, 客户端并不算是HDFS的一部分
• 客户端可以支持打开、 读取、 写入等常见的操作, 并且提供了类似Shell的命令行方式来访问HDFS中的数据
• 此外, HDFS也提供了Java API, 作为应用程序访问文件系统的客户端编程接口
HDFS体系结构的局限性
(1) 命名空间的限制:名称节点是保存在内存中的,因此,名称节点能够容纳的对象(文件、块)的个数会受到内存空间大小的限制。
(2) 性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量。名称节点
(3) 隔离问题:由于集群中只有一个名称节点,只有一个命名空间,因此,无法对不同应用程序进行隔离。
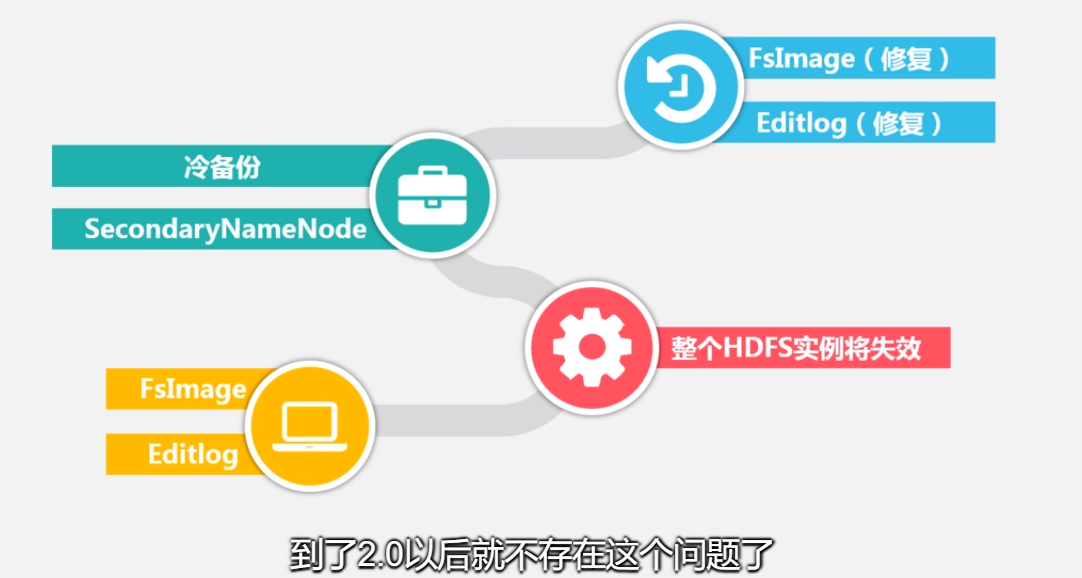
(4) 集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用 。(单点故障,第二名称节点是冷备份!!hdfs1.0) hdfs2.0得到了改善,变成了热备份
HDFS存储原理
冗余数据保存问题 数据保存策略问题 数据恢复问题
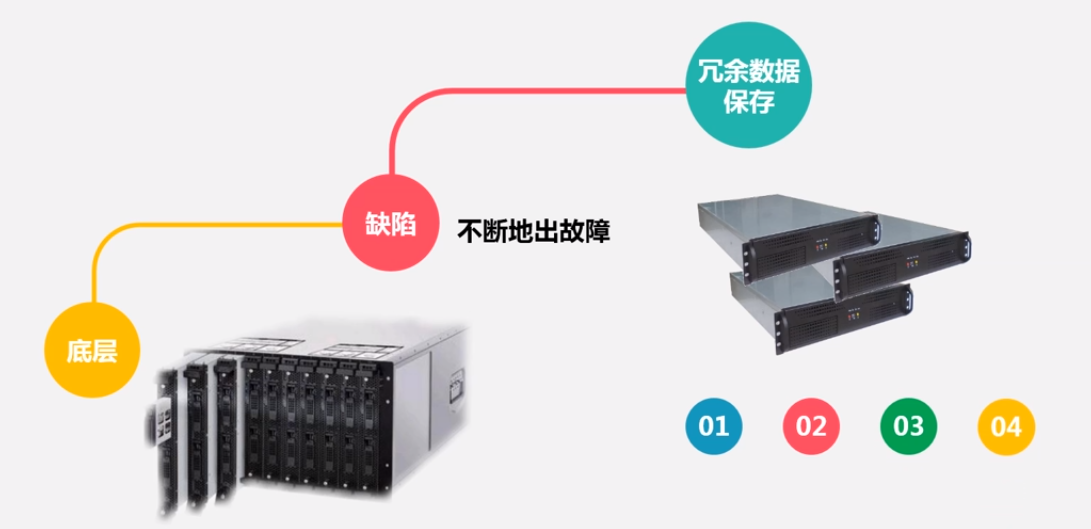
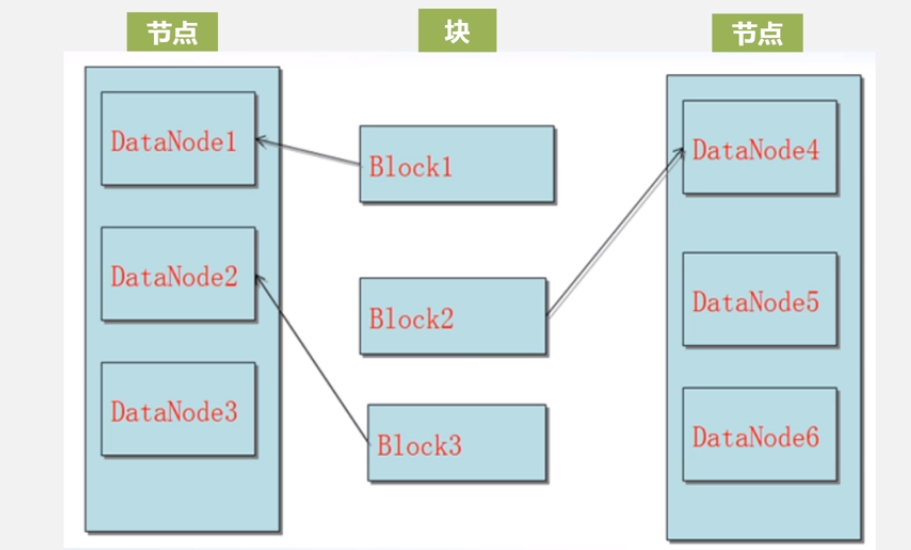
- 数据的冗余存储。
作为一个分布式文件系统,为了保证系统的容错性和可用性, HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上,优点:
(1) 加快数据传输速度
(2) 容易检查数据错误
(3) 保证数据可靠性
- 数据存取策略
- 存储数据:默认是3个副本
一个hdfs集群通常包含多个机架,不同的机架通过交换机或者路由器来数据通信.每个机架上有很多廉价的机器,成为数据节点。
•第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、 CPU不太忙的节点
•第二个副本:放置在与第一个副本不同的机架的节点上
•第三个副本:与第一个副本相同机架的其他节点上
•更多副本:随机节点
读取数据:
就近读取,网络开销小。
怎么知道离客户端近??
•HDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端也可以调用API获取自己所属的机架ID
•当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用API来确定客户端和这些数据节点所属的机架ID,当发现某个数据块副本对应的机架ID和客户端对应的机架ID相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据数据复制:
采用流水线复制策略,提高了效率。
数据错误与恢复

HDFS具有较高的容错性,可以兼容廉价的硬件,它把硬件出错看作一种常态,而不是异常,并设计了相应的机制检测数据错误和进行自动恢复,主要包括以下几种情形:名称节点出错、数据节点出错和数据出错。
名称节点出错
名称节点保存了所有的元数据信息,其中,最核心的两大数据结构是FsImage 和Editlog,如果这两个文件发生损坏,那么整个HDFS实例将失效。因此, HDFS设置了备份机制,把这些核心文件同步复制到备份服务器SecondaryNameNode上。当名称节点出错时,就可以根据备份服务器SecondaryNameNode中的FsImage和Editlog数据进行恢复 .数据节点出错
•每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态
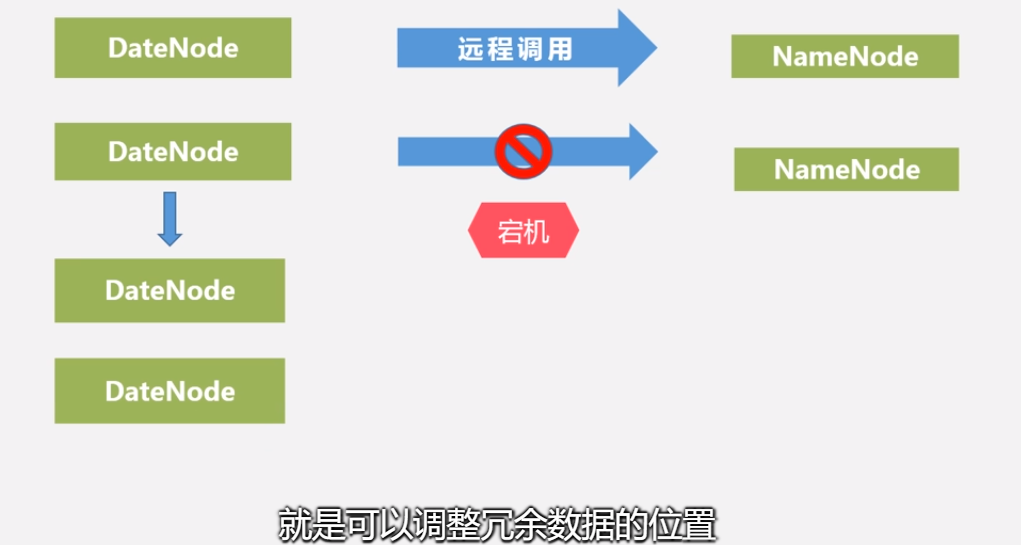
•当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的心跳信息,这时,这些数据节点就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求
•这时,有可能出现一种情形,即由于一些数据节点的不可用,会导致一些数据块的副本数量小于冗余因子
•名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本
•HDFS和其它分布式文件系统的最大区别就是可以调整冗余数据的位置数据出错
•网络传输和磁盘错误等因素,都会造成数据错误
•客户端在读取到数据后,会采用md5和sha1对数据块进行校验,以确定读取到正确的数据
•在文件被创建时,客户端就会对每一个文件块进行信息摘录,并把这些信息写入到同一个路径的隐藏文件里面•当客户端读取文件的时候,会先读取该信息文件,然后,利用该信息文件对每个读取的数据块进行校验,如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块
读写过程
读文件代码:
1 | import java.io.BufferedReader; |
写文件代码:
1 | import org.apache.hadoop.conf.Configuration; |
解释:
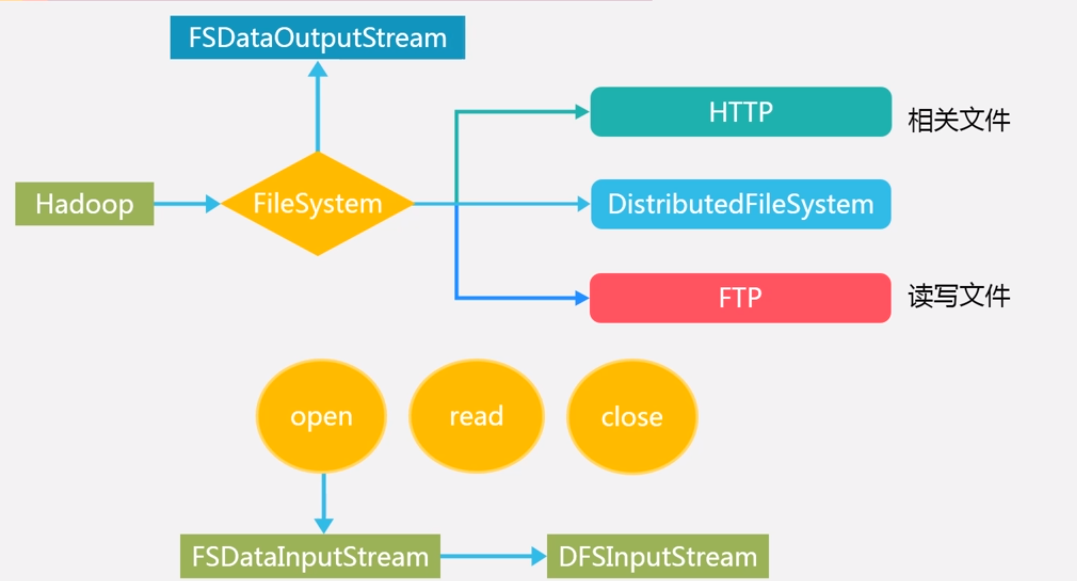
•FileSystem是一个通用文件系统的抽象基类,可以被分布式文件系统继承,所有可能使用Hadoop文件系统的代码,都要使用这个类
•Hadoop为FileSystem这个抽象类提供了多种具体实现
•DistributedFileSystem就是FileSystem在HDFS文件系统中的具体实现•FileSystem的open()方法返回的是一个输入流FSDataInputStream对象,在HDFS文件系统中,具体的输入流就是DFSInputStream; FileSystem中的create()方法返回的是一个输出流FSDataOutputStream对象,在HDFS文件系统中,具体的输出流就是DFSOutputStream。
2
3
4
>FileSystem fs = FileSystem.get(conf);
>FSDataInputStream in = fs.open(new Path(uri));
>FSDataOutputStream out = fs.create(new Path(uri));备注: 创建一个Configuration对象时,其构造方法会默认加载工程项目下两个配置文件,分别是 hdfs-site.xml以及core-site.xml,这两个文件中会有访问HDFS所需的参数值,主要是fs.defaultFS(指定了HDFS的地址(比如hdfs://localhost:9000)) ,有了这个地址客户端就可以通过这个地址访问HDFS了
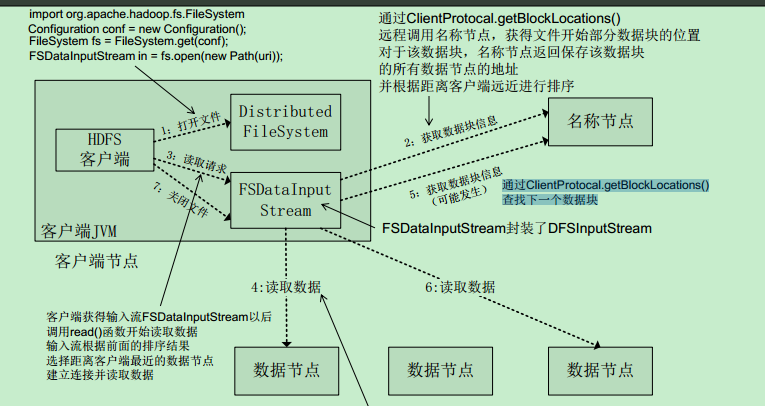
读文件具体过程:
看图:
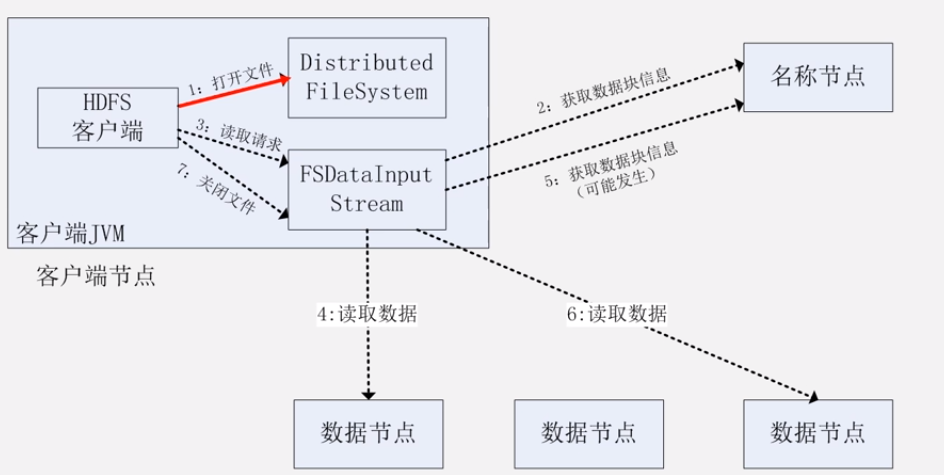
客户端调用 open(),read(),close() 读取数据
1.打开文件
1
2
3
4
5
6
7
8
9
10
//生成了:FileSystem其实是个 DistributedFileSystem
//操作:通过FileSystem.open()打开文件
import org.apache.hadoop.fs.FileSystem
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);//生成了:FileSystem其实是个 DistributedFileSystem
FSDataInputStream in = fs.open(new Path(uri));//创建输入流。uri文件地址
//封装了DFSInputStream,由它来真正和名称节点打交道。
2.获取数据块信息
DFSInputStream的构造函数通过ClientProtocal.getBlockLocations()
远程调用名称节点,获得文件开始部分数据块的位置
对于该数据块,名称节点返回保存该数据块的所有数据节点的地址并根据距离客户端远近进行排序
DistributedFileSystem利用DFSInputStream来实例化FSDataInputStream,返回给客户端。
- 读取请求 read()函数
客户端获得输入流FSDataInputStream以后调用read()函数开始读取数据
输入流根据前面的排序结果
选择距离客户端最近的数据节点
建立连接并读取数据客户端获得输入流FSDataInputStream以后 调用read()函数开始读取数据
输入流根据前面的排序结果
选择距离客户端最近的数据节点
建立连接并读取数据客户端获得输入流FSDataInputStream以后 调用read()函数开始读取数据
输入流根据前面的排序结果
选择距离客户端最近的数据节点
建立连接并读取数据
读取数据
数据从数据节点读到客户端,当该数据块读取完毕时
FSDataInputStream关闭和该数据节点的连接 (可能没读完)
5.再次获取数据块信息(不一定发生)
通过ClientProtocal.getBlockLocations()
查找下一个数据块- 找到数据节点,读取数据
- FSDataInputStream 的close()函数。
写文件具体过程:
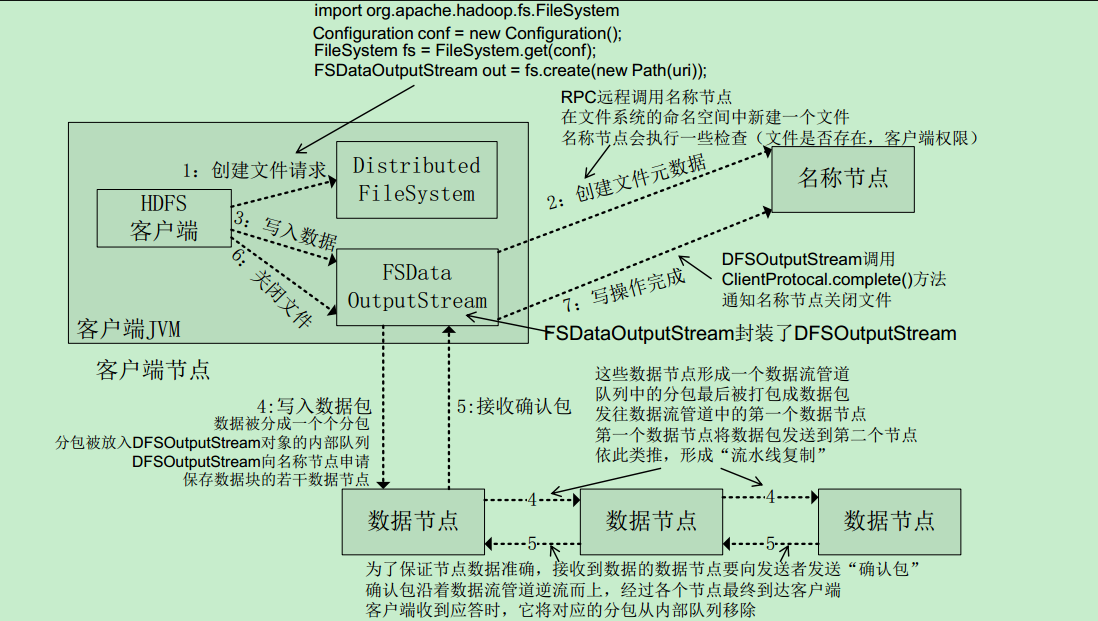
FSDataOutputStream,
客户端连续调用 create(),write(),close()等方法
- 创建文件请求
1
2
3
4
5//FileSystem.create()创建文件,由DistributedFileSystem创建输出流FSDataOutputStream,里面封装了DFSOutputStream
import org.apache.hadoop.fs.FileSystem
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
FSDataOutputStream out = fs.create(new Path(uri));创建文件元数据
RPC远程调用名称节点
在文件系统的命名空间中新建一个文件
名称节点会执行一些检查(文件是否存在,客户端权限)远程方法调用结束后,DistributedFileSystem 会利用DFSOutputStream来实例化FSDataOutputStream,返回给客户端,来使用以达写入数据。
- 写入数据,通过调用write()
写入数据包
数据被分成一个个分包
分包被放入DFSOutputStream对象的内部队列
DFSOutputStream向名称节点申请
保存数据块的若干数据节点流水性复制:数据由数据节点形成数据管道来一个个复制,流水线,再由数据节点来一个个通知写入成功。以达第5步。
接收确认 包
这些数据节点形成一个数据流管道
队列中的分包最后被打包成数据包
发往数据流管道中的第一个数据节点
第一个数据节点将数据包发送到第二个节点
依此类推,形成“流水线复制”确认则流程相反,直到客户端呢
关闭文件
客户端通知,通过close关闭输入流
编程
《大数据技术原理与应用 第三章 Hadoop分布式文件系统 学习指南》
访问地址: http://dblab.xmu.edu.cn/blog/290-2/
备注:
备注: Hadoop中有三种Shell命令方式:
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
分布式数据库HBase
分布式数据库。
概述
BigTable
谷歌公司的BigTable
BigTable是一个分布式存储系统
BigTable起初用于解决典型的互联网搜索问题
怎么使用呢??
•建立互联网索引
1 网络爬虫持续不断地抓取新页面,这些页面每页一行地存储到BigTable里
2 MapReduce计算作业运行在整张表上,生成索引,为网络搜索应用做准备•搜索互联网
3 用户发起网络搜索请求
4 网络搜索应用查询建立好的索引,从BigTable得到网页
5 搜索结果提交给用户
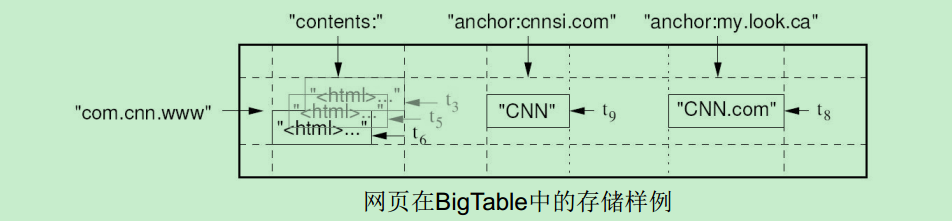
•BigTable是一个分布式存储系统
底层是GFS,负责存储。
•利用谷歌提出的MapReduce分布式并行计算模型来处理海量数据
•使用谷歌分布式文件系统GFS作为底层数据存储
•采用Chubby提供协同服务管理•可以扩展到PB级别的数据和上千台机器,具备广泛应用性、可扩展性、高性能和高可用性等特点
•谷歌的许多项目都存储在BigTable中,包括搜索、地图、财经、打印、社交网站Orkut、视频共享网站YouTube和博客网站Blogger等
HBase 简介
HBase是一个高可靠、高性能、**面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。 HBase的目标是处理非常庞大的表,可以通过水平扩展**的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表

HBase和BigTable的底层技术对应关系
| BigTable | HBase | |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | Zookeeper |
为什么需要HBase??

•Hadoop可以很好地解决大规模数据的离线批量处理问题,但是,受限于HadoopMapReduce编程框架的高延迟数据处理机制,使得Hadoop无法满足大规模数据实时处理应用的需求
•HDFS面向批量访问模式,不是随机访问模式
•传统的通用关系型数据库无法应对在数据规模剧增时导致的系统扩展性和性能问题(分库分表也不能很好解决)
•传统关系数据库在数据结构变化时一般需要停机维护;空列浪费存储空间
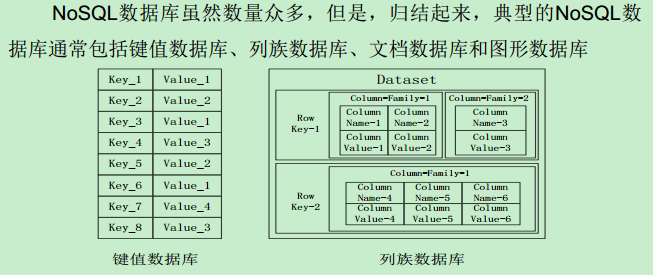
•因此,业界出现了一类面向半结构化数据存储和处理的高可扩展、低写入/查询延迟的系统,例如,键值数据库、文档数据库和列族数据库(如BigTable和HBase等)
•HBase已经成功应用于互联网服务领域和传统行业的众多在线式数据分析处理系统中
HBase与传统关系数据库的对比分析 :
• HBase与传统的关系数据库的区别主要体现在以下几个方面:
• (1)数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串,由开发人员读取后再处理。
• (2)数据操作:关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表和表之间的关系
• (3)存储模式:关系数据库是基于行模式存储的。 HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的• (4)数据索引:关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。 HBase只有一个索引——行键,通过巧妙的设计, HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来
• (5)数据维护:在关系数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数 据旧的版本,而是生成一个新的版本,旧有的版本仍然保留,时间戳。
• (6)可伸缩性:关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反, HBase和BigTable这些分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩
HBase 访问接口
编程一般用java api:或shell
| 类型 | 特点 | 场合 |
|---|---|---|
| Native Java API | 最常规和高效的访问方式 | 适合Hadoop MapReduce作业并行批 处理HBase表数据 |
| HBase Shell | HBase的命令行工具,最简单 的接口 | 适合HBase管理使用 |
| Thrift Gateway | 利用Thrift序列化技术,支持 C++、 PHP、 Python等多种语 言 | 适合其他异构系统在线访问HBase表 数据 |
| REST Gateway | 解除了语言限制 | 支持REST风格的Http API访问HBase |
| Pig | 使用Pig Latin流式编程语言来 处理HBase中的数据(类似sql) | 适合做数据统计 |
| Hive | 简单 (类似sql) | 当需要以类似SQL语言方式来访问 HBase的时候 |
HBase数据模型
关键词:
数据模型概述
数据模型相关概念
数据坐标
概念视图
物理视图
面向列的存储
概述
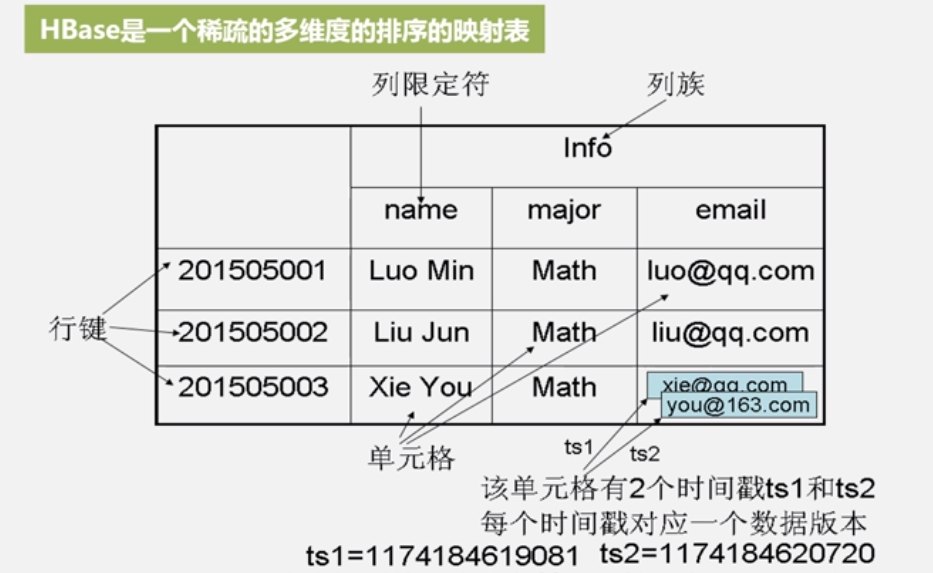
• 表: HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
• 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
• 列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元
• 列限定符:列族里的数据通过列限定符(或列)来定位
• 单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
• 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
• HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳
• 每个值是一个未经解释的字符串,没有数据类型
• 用户在表中存储数据,每一行都有一个可排序的行键和任意多的列
• 表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起
• 列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换
• HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的,HBase架构在hdfs之上)
- 数据坐标
• HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此,可以视为一个“四维坐标”,即[行键, 列族, 列限定符, 时间戳]
| 键 | 值 |
|---|---|
| [―201505003‖, ―Info‖, ―email‖, 1174184619081] | “xie@qq.com‖ |
| [―201505003‖, ―Info‖, ―email‖, 1174184620720] | “you@163.com‖ |
概念视图与物理视图
- 概念视图:我们看上去的结构
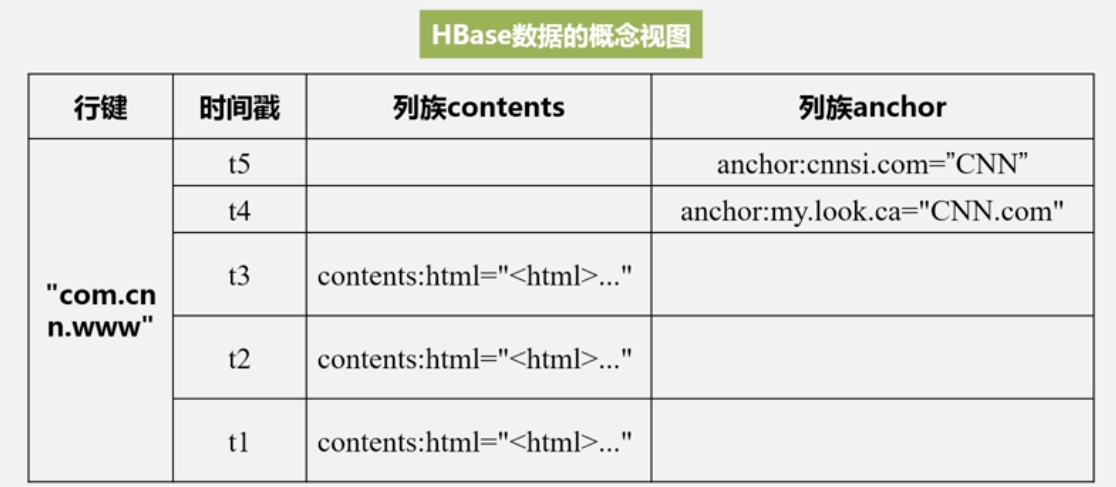
概念上是稀疏表。
物理视图:实际存储
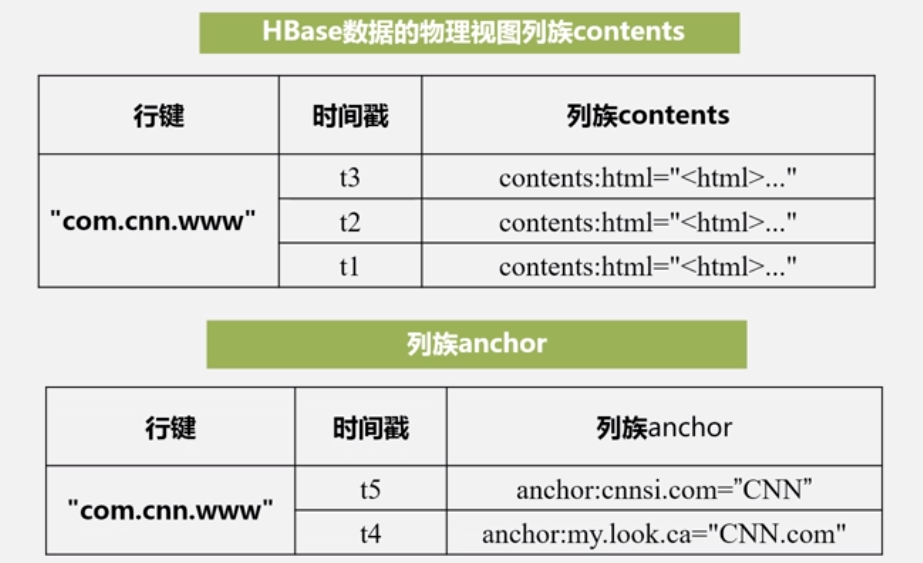
按列族存储,没有那么多的空格。
底层是按列族为单位进行存储。与行键,时间戳相分配结合。
面向列的存储
面向行的数据库,与面向列的数据库。
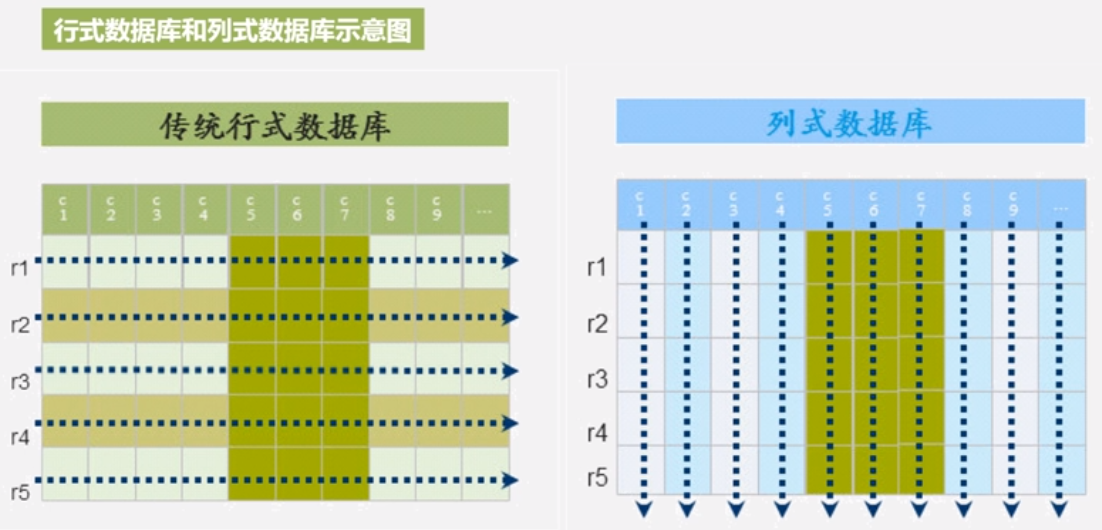
面向行的数据存储:
优缺点:
优: 一次写完整一行记录。事物型操作,OLTP系统。
缺: 要取出,扫描许多行,却只一些字段。列分析代价大

面向列的数据存储:
高数据压缩率(数据类型大多相似)。
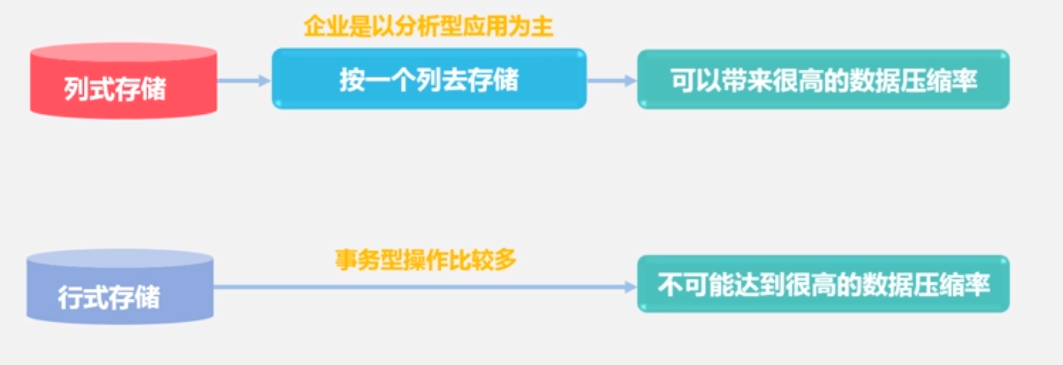
实现原理
HBase功能组件
表和Region
Region的定位
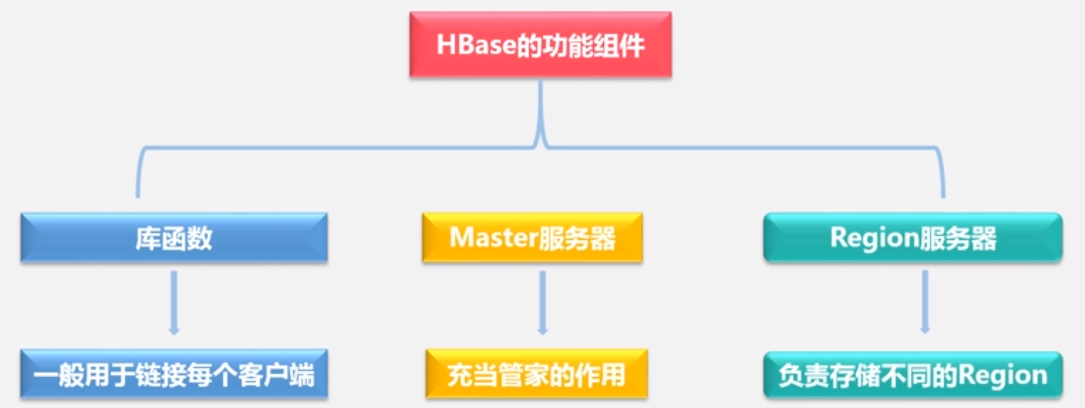
功能组件
• HBase的实现包括三个主要的功能组件:
– (1)库函数:链接到每个客户端
– (2)一个Master主服务器1
>• 主服务器Master负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡
—(3)许多个Region服务器
一个大的表被分为很多个Region
Region
Region是表按照RowKey范围划分的不同的部分,相当于DBMS中的分区。同时Region也是表在集群中分布的最小单位,可以被分配到某一个Region Server上。Region是HBase的表分区,是数据分片的概念。HBase中表有多个region分区组成。region由一组rowkey有序的行组成。
1
2>• Region服务器负责存储和维护分配给自己的Region,处理来自客户端的读写请求
• 客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据
• 客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小
表和Region
**一个HBase表被划分成多个Region **:一个表可能在多个服务器上
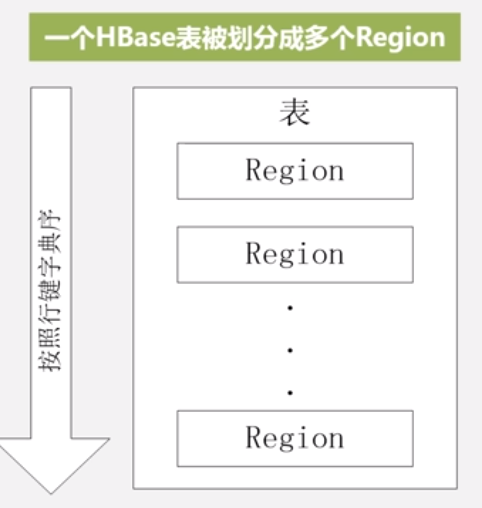
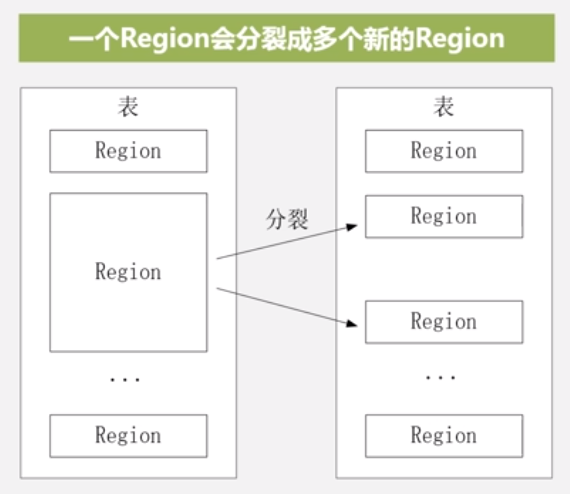
•开始只有一个Region,后来不断分裂
•Region拆分操作非常快,接近瞬间,因为拆分之后的Region读取的仍然是原存储文件,(修改的之时指向哪里的区别)直到“合并”过程把存储文件异步地写到独立的文件之后,才会读取新文件 .
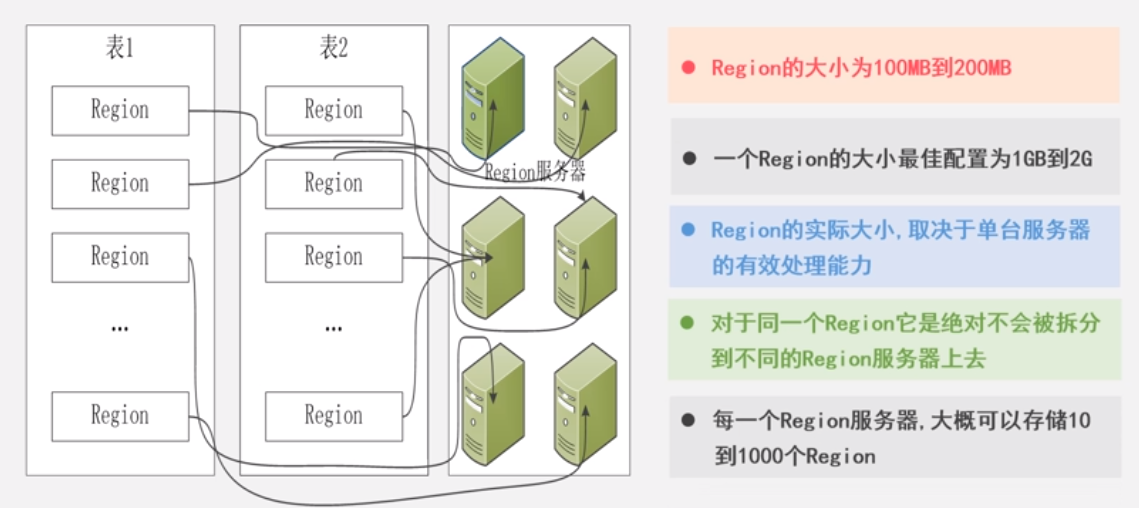
region的配置:
大小:
•每个Region默认大小是100MB到200MB(2006年以前的硬件配置)
•每个Region的最佳大小取决于单台服务器的有效处理能力
•目前每个Region最佳大小建议1GB-2GB(2013年以后的硬件配置)位置:
•同一个Region不会被分拆到多个Region服务器(由Master)服务器来配置
•每个Region服务器存储10-1000个Region
region定位问题:
•元数据表,又名.META.表,存储了Region和Region服务器的映射关系
构建一个元素据表,里面有两项内容;构成映射
- region id
- region 服务器 id
随着数据增加,元素据表也会变得很大,他的存储也需要分裂成多个region,但是这样的话.meta表就分散开来了,所以我们得构造一个新表,也就是
-ROOT-表•当HBase表很大时, .META.表也会被分裂成多个Region
•根数据表,又名-ROOT-表,记录所有元数据的具体位置
•-ROOT-表只有唯一一个Region,名字是在程序中被写死的
•Zookeeper文件记录了-ROOT-表的位置类似B+树
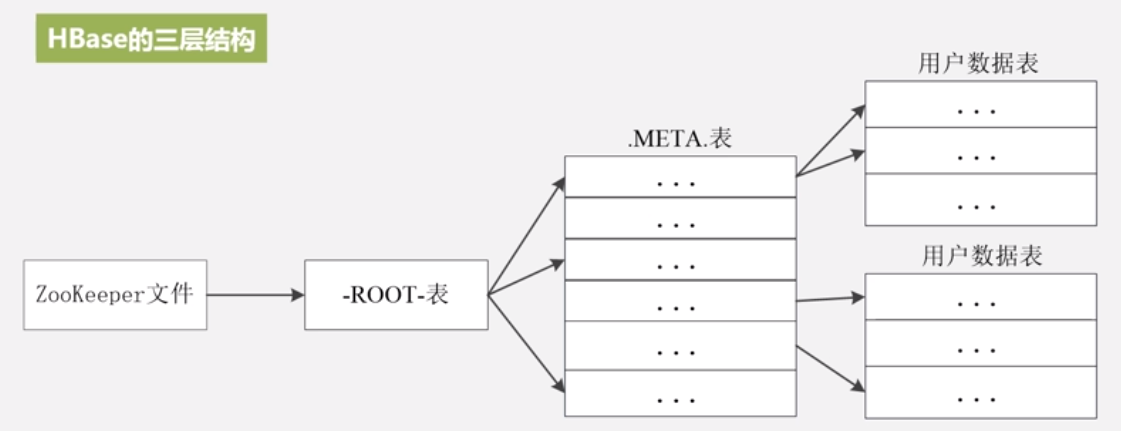
客户端访问region:
-ROOT-的地址在zookeeper里,客户端先访问zookeeper。
三级寻找过程
| 层次 | 名称 | 作用 |
|---|---|---|
| 第一层 | Zookeeper文 件 | 记录了-ROOT-表的位置信息 |
| 第二层 | -ROOT-表 | 记录了.META.表的Region位置信息 -ROOT-表只能有一个Region。通过-ROOT- 表,就可以访问.META.表中的数据 |
| 第三层 | .META.表 | 记录了用户数据表的Region位置信息, .META.表可以有多个Region,保存了HBase 中所有用户数据表的Region位置信息 |
与内存相关:
•为了加快访问速度, .META.表的全部Region都会被保存在内存中
•假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为128MB,那么,上面的三层结构可以保存的用户数据表的Region数目的计算方法是:
- (-ROOT-表能够寻址的.META.表的Region个数)×(每个.META.表的 Region可以寻址的用户数据表的Region个数)
- 一个-ROOT-表最多只能有一个Region,也就是最多只能有128MB,按照每行(一个映射条目)占用1KB内存计算, 128MB空间可以容纳128MB/1KB=2^17行,也就是说,一个-ROOT- 表可以寻址2^17个.META.表的Region。
- 同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是128MB/1KB=2^17 .
- 最终,三层结构可以保存的Region数目是(128MB/1KB) × (128MB/1KB) = 2^34个Region
客户端访问数据时的“三级寻址”:带来的问题
•为了加速寻址,客户端会缓存位置信息,同时,需要解决缓存失效问题
•寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器
惰性解决方式: 碰到失效了,再重新寻一次址。
HBase 运行机制
HBase系统架构:
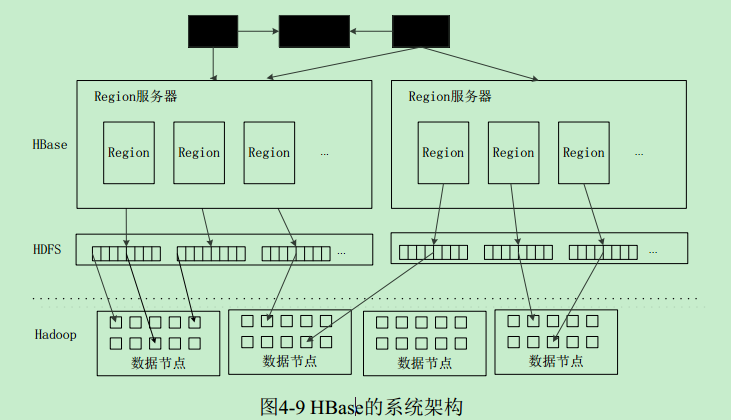
• 1. 客户端
– 客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程
• 2. Zookeeper服务器:协同管理服务
– Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题,Zookeeper是一个很好的集群管理工具,被大量用于分布式计算,提供配置维护、域名服务、分布式同步、组服务等。
• 3. Master
• 主服务器Master主要负责表和Region的管理工作:
– 管理用户对表的增加、删除、修改、查询等操作
– 实现不同Region服务器之间的负载均衡:重新分配Region,把重负载的放到轻负载的服务器上。
– 在Region分裂或合并后,负责重新调整Region的分布
– 对发生故障失效的Region服务器上的Region进行迁移
• 4. Region服务器
– Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
Region服务器工作原理
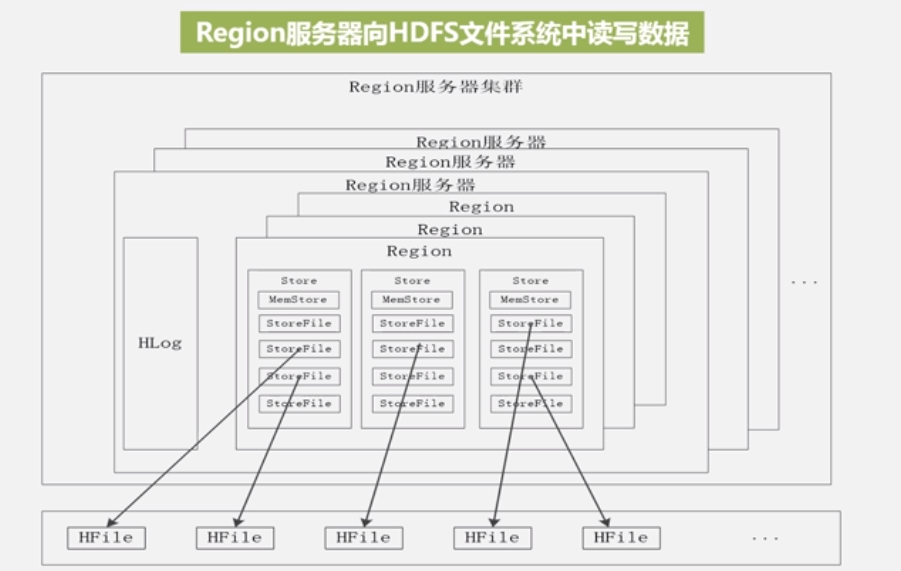
整体概况 :好多的Region服务器组成Region服务器集群
Region服务器是HBase最核心的模块,管理一系列的Region对象和一个HLog文件。
HLog:磁盘上面的记录文件,记录者所有更新操作。
每个Region又是由多个Store组成的,
每个Store对应表中的一个列族存储,包含一个MemStore和若干个StoreFile:
其中,MemStore是在内存中的缓存,刷新满了之后再写到StoreFile中去,保存最近跟新的数据,StoreFile是磁盘中的文件,结构是B+树结构,方便快速读取。StoreFile在底层的实现方式是HDFS文件系统的HFile,HFile的数据块通常使用压缩方式存储,压缩之后可以大大减少网络I/O和磁盘I/O.
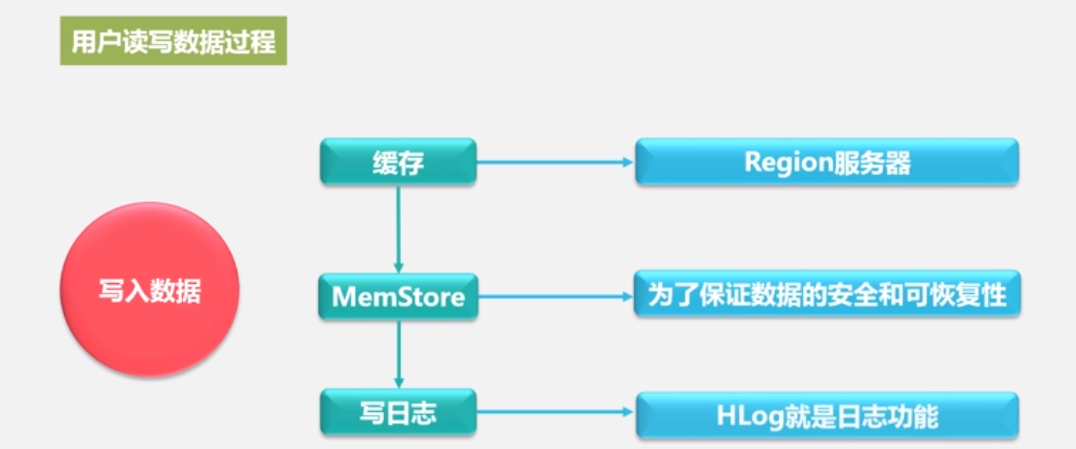
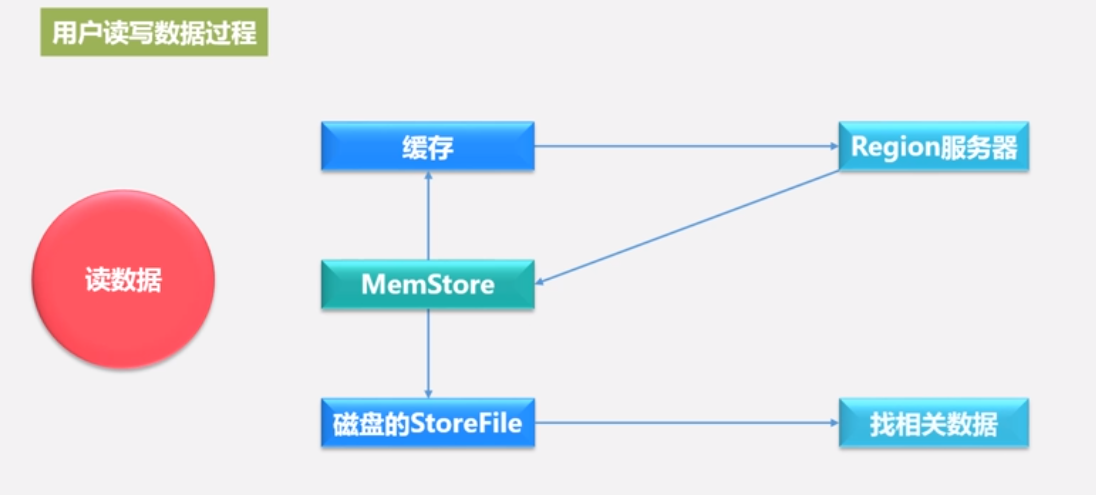
用户读取数据过程
•用户写入数据时,被分配到相应Region服务器去执行
•用户数据首先被写入到MemStore和Hlog(为保证数据的安全和可恢复性)中
•只有当操作写入Hlog之后(也就是写入磁盘了), commit()调用才会将其返回给客户端
•当用户读取数据时, Region服务器会首先访问MemStore缓存,如果找不到,再去磁盘上面的StoreFile中寻找
缓存刷新
注意:一个Region服务器只有一个HLog文件。
也就是,StoreFile与MemStore的关系了
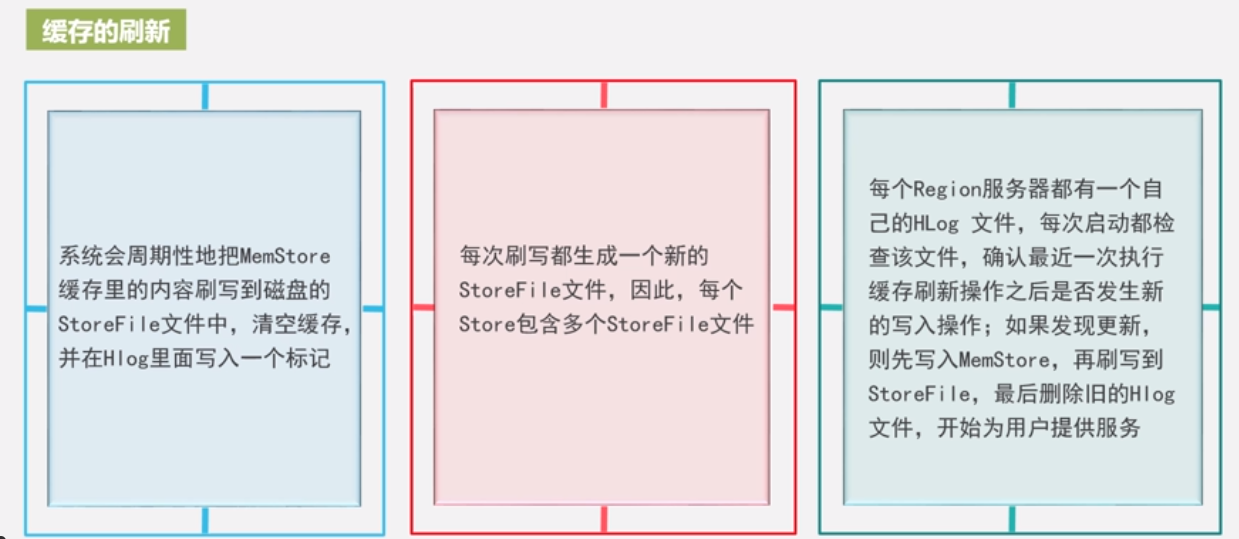
•系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记
•每次刷写都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件
•每个Region服务器都有一个自己的HLog 文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧 的Hlog文件,开始为用户提供服务
StoreFile的合并与分裂
好多个storefile合并成一个strorefile:A,A再分裂成几个小strorefile
合并需要很大的资源,所以只有一定的阈值才会执行这个操作。
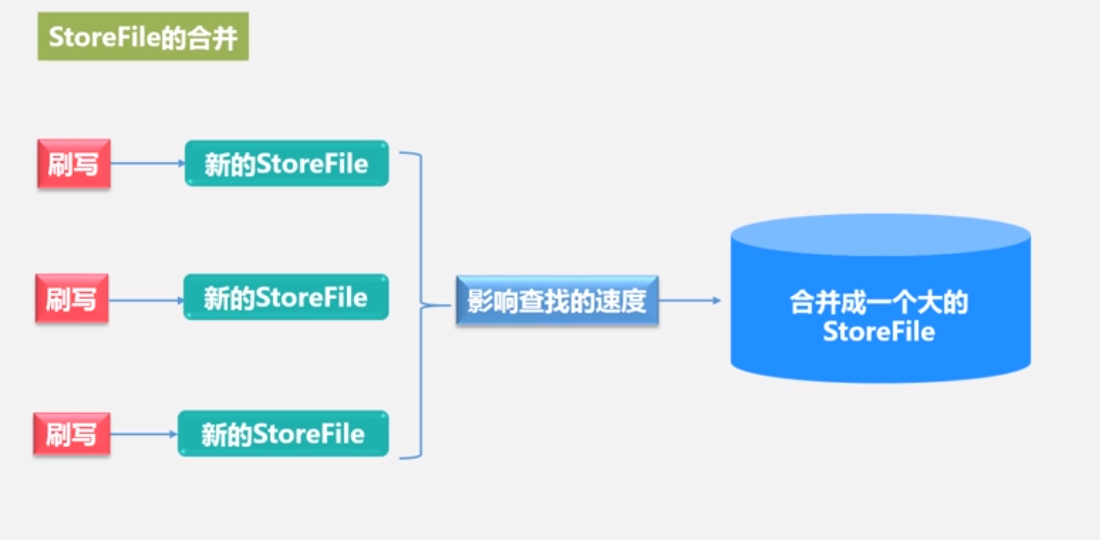
•每次刷写都生成一个新的StoreFile,数量太多,影响查找速度
•调用Store.compact()把多个合并成一个
•合并操作比较耗费资源,只有数量达到一个阈值才启动合并
合并又会出现问题:此时又会分裂,此时也就产生了Region的分裂。
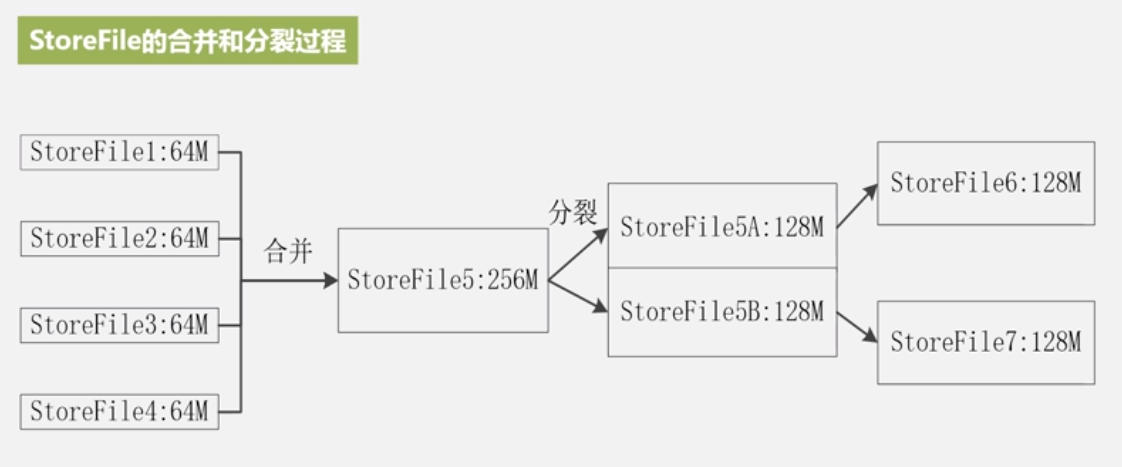
Store工作原理
•Store是Region服务器的核心
•多个StoreFile合并成一个
•单个StoreFile过大时,又触发分裂操作, 1个父Region被分裂成两个子Region
HLog工作原理
考虑系统出错,而产生的日志方法。(处理的是HLog日志)
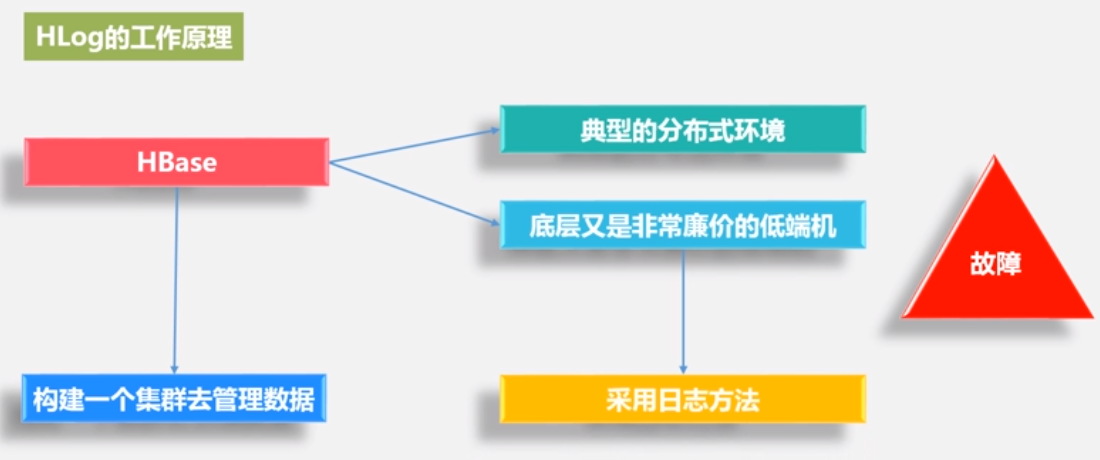
• 分布式环境必须要考虑系统出错。 HBase采用HLog保证系统恢复
• HBase系统为每个Region服务器配置了一个HLog文件,它是一种 预写式日志(Write Ahead Log):先记录日志,才能写入缓存。
• 用户更新数据必须首先写入日志后,才能写入MemStore缓存,并且,直到MemStore缓存内容对应的日志已经写入磁盘,该缓存内容才能被刷写到磁盘 .
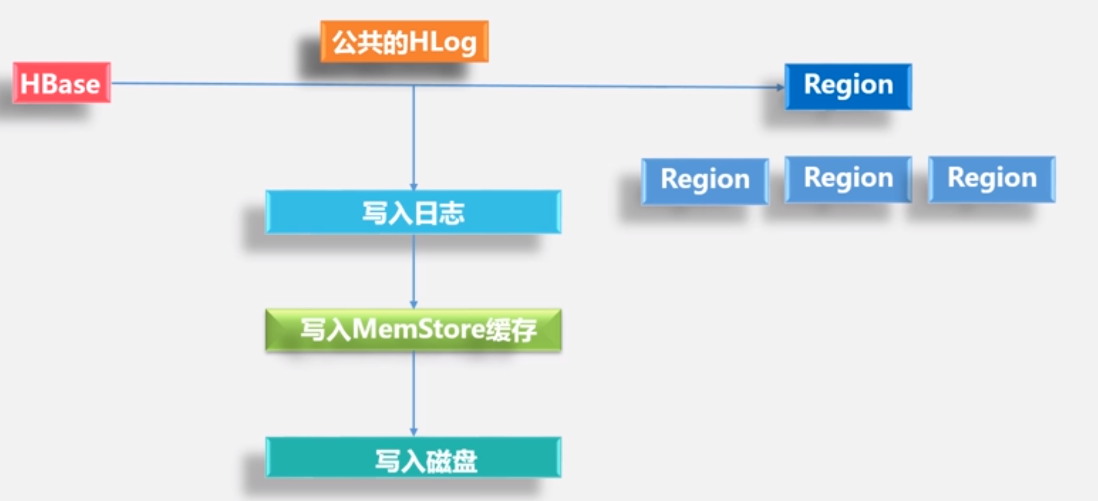
zookeeper来知道哪里出问题:Zookeeper会实时监测每个Region服务器的状态,当某个Region服务器发生故障时, Zookeeper会通知Master 。
怎么恢复呢???
- Master首先会处理该故障Region服务器上面遗留的HLog文件,这个遗留的HLog文件中包含了来自多个Region对象的日志记录 .
- 系统会根据每条日志记录所属的Region对象对HLog数据进行拆分,分别放到相应Region对象的目录下,然后,再将失效的Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日 **志记录也发送给相应的Region服务器 .**(处理的是HLog日志)
- Region服务器领取到分配给自己的Region对象以及与之相关的HLog日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入到MemStore缓存中,然后,刷新到磁盘的StoreFile文件中,完成数据恢复 .
• 共用日志优点(一台Region服务器只有一个HLog):提高对表的写操作性能;缺点:恢复时需要分拆日志
一个Region服务器只有一个HLog,而不是多个HLog,方便读取写入,不方便故障恢复。
但是主流不是故障恢复,毕竟故障不常有。
HBase 应用方案
性能优化
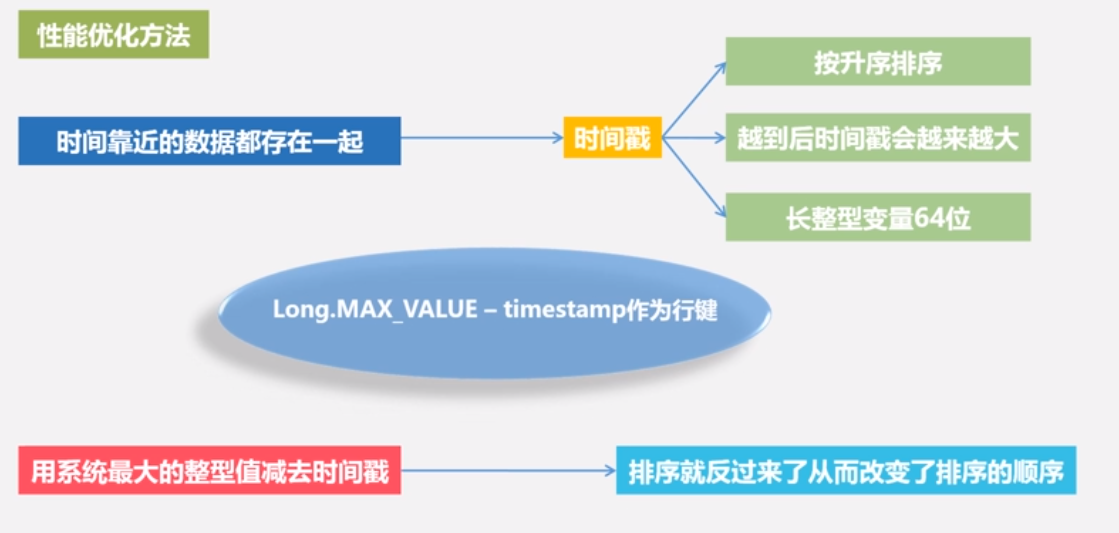
- 某些数据靠近在一起,时间靠近的数据放在一起。
- 事实性,读写性能比较高
- 提升读写性能:设置HColumnDescriptor.setInMemory选项为True,以把相关的表放到Region服务器的缓存当中。根据需要来决定是否放入缓存。
行键:
行键是按照字典序存储,因此,设计行键时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入HBase表中的数据是最可能被访问的,可以考虑将时间戳作为行键的一部分,由于是字典序排序,所以可以使用Long.MAX_VALUE -timestamp作为行键,这样能保证新写入的数据在读取时可以被快速命中。
InMemory 是否在内存中
创建表的时候,可以通过HColumnDescriptor.setInMemory(true)将表放到Region服务器的缓存中,保证在读取的时候被cache命中。
•InMemory
Max Version 最大版本数
创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1)。
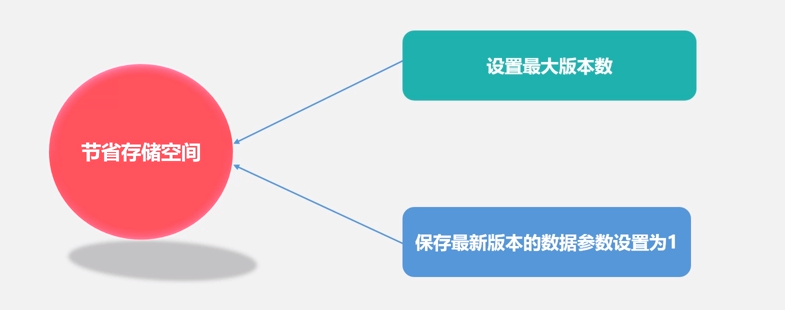
时间过了很久还没到最大版本数,数据也没用了。
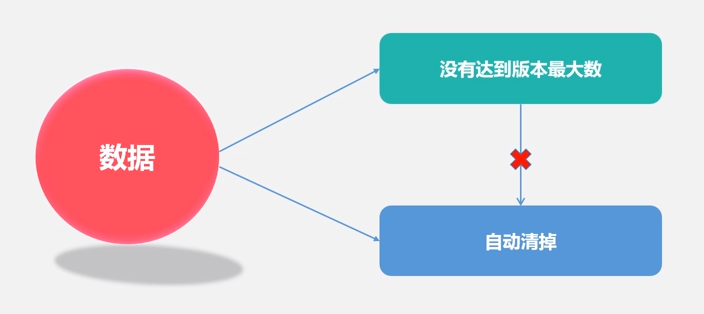
Time To Live 自动删除数据,生命周期
创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置setTimeToLive(2 * 24 * 60 * 60)。
HBase性能监视
工具:
•Master-status(自带)
•HBase Master默认基于Web的UI服务端口为60010, HBase region服务器默 认基于Web的UI服务端口为60030.如果master运行在名为master.foo.com的主机中, mater的主页地址就是
http://master.foo.com:60010,用户可以通过Web浏览器输入这个地址查看该页面
•可以查看HBase集群的当前状态
•Ganglia
Ganglia是UC Berkeley发起的一个开源集群监视项目,用于监控系统性能
•OpenTSDB
OpenTSDB可以从大规模的集群(包括集群中的网络设备、操作系统、应用程序)中获取相应的metrics并进行存储、索引以及服务,从而使得这些数据更容易让人理解,如web化,图形化等
•Ambari
Ambari 的作用就是创建、管理、监视 Hadoop 的集群
在HBase之上构建SQL引擎
使用sql语句操作HBase
- NoSQL区别于关系型数据库的一点就是NoSQL不使用SQL作为查询语言,至于为何在NoSQL数据存储HBase上提供SQL接口,有如下原因:
- 1.易使用。使用诸如SQL这样易于理解的语言,使人们能够更加轻松地使用HBase。
- 2.减少编码。使用诸如SQL这样更高层次的语言来编写,减少了编写的代码量。
如何构建:
方案:
- Hive整合HBase
Hive与HBase的整合功能从Hive0.6.0版本已经开始出现,利用两者对外的API接口互相通信,通信主要依靠hive_hbase-handler.jar工具包(Hive Storage Handlers)。由于HBase有一次比较大的版本变动,所以并不是每个版本的Hive都能和现有的HBase版本进行整合,所以在使用过程中特别注意的就是两者版本的一致性。
- Phoenix
Phoenix由Salesforce.com开源,是构建在Apache HBase之上的一个SQL中间层,可以让开发者在HBase上执行SQL查询。
构建HBase二级索引
二级索引的概念:
二级索引,又叫辅助索引
关系数据库里,如学生表对学号字段进行 主索引(Primary Key),然后对姓名和学号字段等构建多个辅助索引或者说二级索引。
而HBase只有一个针对行健的索引 。
访问HBase:
访问HBase表中的行,只有三种方式:
•通过单个行健访问
•通过一个行健的区间来访问
•全表扫描

实际上可能分析不同的列,那就需要索引了
所以,考虑构建二级索引
使用其他产品为HBase行健提供索引功能:
•Hindex二级索引
•HBase+Redis
•HBase+solr
原理:采用HBase0.92版本之后引入的Coprocessor特性 ,而开发一些工具来构建
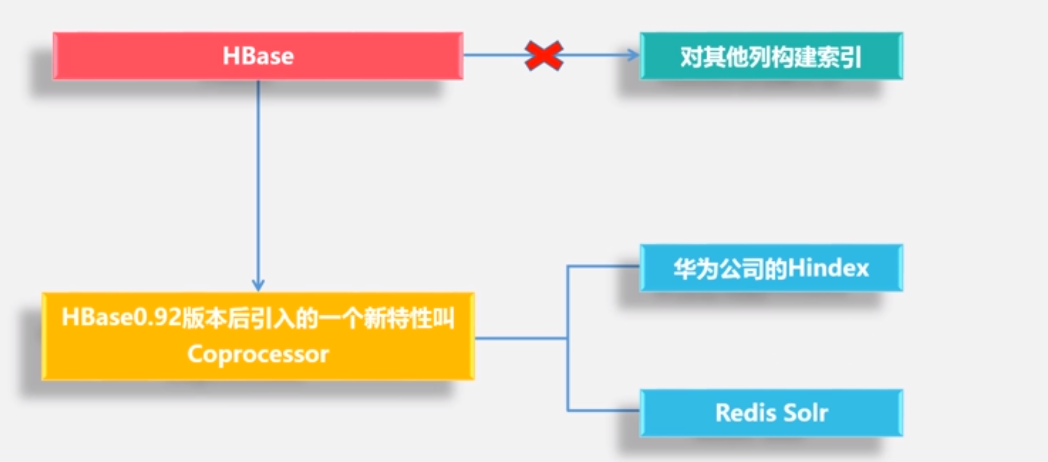
Coprocessor:endpoint和observer,
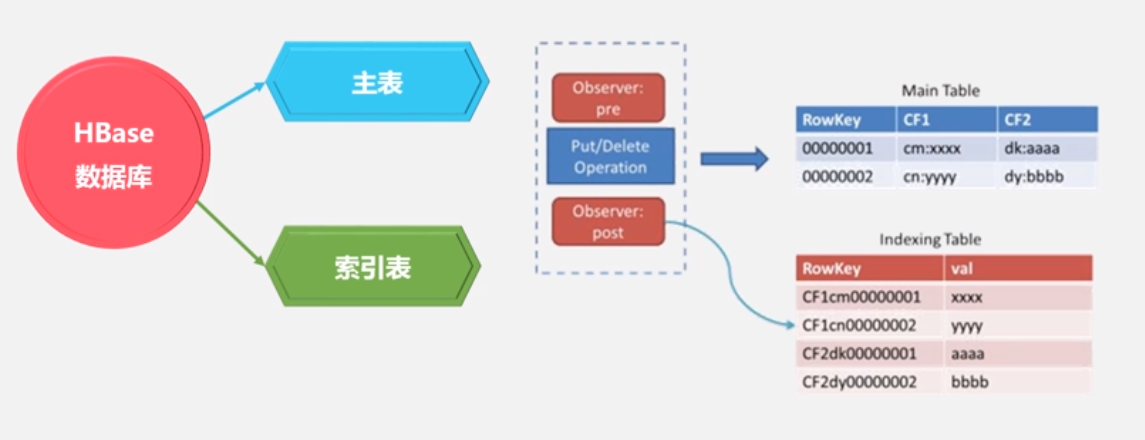
Coprocessor怎么构建二级索引
•Coprocessor提供了两个实现: endpoint和observer, endpoint相当于关系型数据库的存储过程,而observer则相当于触发器
•observer允许我们在记录put前后做一些处理,因此,而我们可以在插入数据时同步写入索引表 .
优点
非侵入性:引擎构建在HBase之上,
既没有对HBase进行任何改动,也
不需要上层应用做任何妥协缺点
每插入一条数据需要向索
引表插入数据,即耗时是双倍的,
对HBase的集群的压力也是双倍
的从而产生主表与索引表。
- 像华为通过Coprocessor的这种机制而开发的:Hindex
Hindex 是华为公司开发的纯 Java 编写的HBase二级索引,兼容 Apache HBase 0.94.8。当前的特性如下:
•多个表索引
•多个列索引
•基于部分列值的索引注:索引表一般存储在磁盘中,而频发的更新索引表代价就很高。所以考虑以下方案
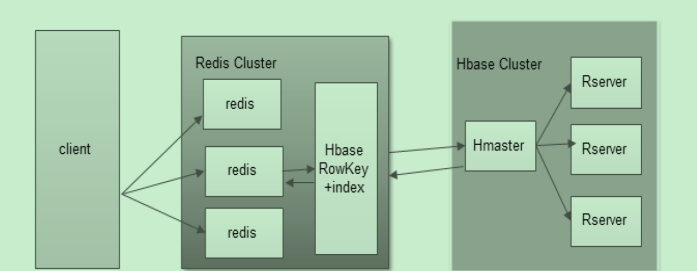
Redis+HBase方案
•Coprocessor构建二级索引
•Redis做客户端缓存
•将索引实时更新到Redis等KV系统中,定时从KV更新索引到HBase的索引表中
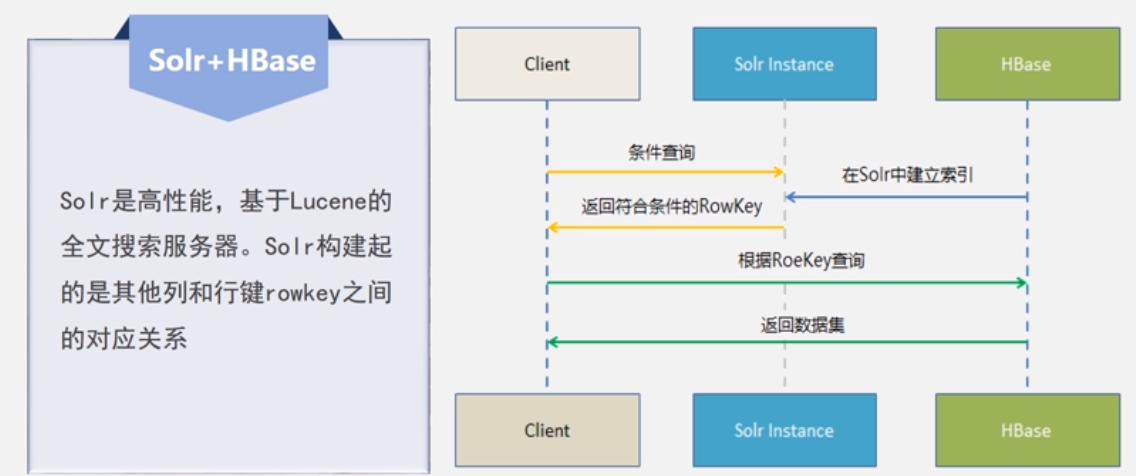
Solr+HBase
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。 Solr保存索引 。
Solr先构建对其他列的全文索引,再由搜索值对应一行的某个信息,从而找到那个值所对应信息的行键
HBase安装和配置 shell
HBase上机实践,请参考:《大数据原理与应用 第四章 分布式数据库HBase 学习指南》
http://dblab.xmu.edu.cn/blog/588-2/
安装完Hadoop时,只包含HDFS和MapReduce等核心组件,并不包含HBase,因此, HBase需要单独安装
HBase 自己带了一个zookeeper 实验用就够了。
但是你也可以自己装一个zookeeper。
HBase安装
•下载安装包hbase-1.1.2-bin.tar.gz
•解压安装包hbase-1.1.2-bin.tar.gz至路径 /usr/local
•配置系统环境,将hbase下的bin目录添加到系统的path中
启动关闭Hadoop和HBase的顺序一定是:
启动Hadoop—>启动HBase—>关闭HBase—>关闭Hadoop
HBASE_MANAGES_ZK=true,则由HBase自己管理Zookeeper
安装注意事项

HBase Shell 命令
http://dblab.xmu.edu.cn/blog/install-hbase/
创建表
1 | create 'tablename','l1','l2','l3' |
list:列出HBase中所有的表信息
put
向表、行、列指定的单元格添加数据,一次只能为一个表的一行数据的一个列添加一个数据
scan:浏览表的相关信息
在添加数据时, HBase会自动为添加的数据添加一个时间戳,当然,也可以在添
加数据时人工指定时间戳的值
get
通过表名、行、列、时间戳、时间范围和版本号来获得相应单元格的值
enable/disable:使表有效或无效
drop:删除表
首先必须让表失效!!!
Java API编程实例
http://dblab.xmu.edu.cn/blog/install-hbase/
NoSQL数据库
Not only SQL
NoSQL简介
通常, NoSQL数据库具有以下几个特点:
(1)灵活的可扩展性,水平扩展
(2)灵活的数据模型
(3)与云计算紧密融合,根据负载调整服务器数量
为什么要有NoSQL
1、 关系数据库已经无法满足Web2.0的需求。 主要表现在以下几个方面:
(1)无法满足海量数据的管理需求
(2)无法满足数据高并发的需求
(3)无法满足高可扩展性和高可用性的需求
MySQL集群是否可以完全解决问题?
•复杂性:部署、管理、配置很复杂
•数据库复制: MySQL主备之间采用复制方式,只能是异步复制,当主库压力较大时可能产生较大延迟,主备切换可能会丢失最后一部分更新事务,这时往往需要人工介入,备份和恢复不方便
•扩容问题:如果系统压力过大需要增加新的机器,这个过程涉及数据重新划分,整个过程比较复杂,且容易出错
•动态数据迁移问题:如果某个数据库组压力过大,需要将其中部分数据迁移出去,迁移过程需要总控节点整体协调,以及数据库节点的配合。这个过程很难做到自动化
2、“One size fits all”模式很难适用于截然不同的业务场景
•关系模型作为统一的数据模型既被用于数据分析,也被用于在线业务。但这两者一个强调高吞吐,一个强调低延时,已经演化出完全不同的架构。用同一套模型来抽象显然是不合适的
•Hadoop就是针对数据分析
•MongoDB、 Redis等是针对在线业务,两者都抛弃了关系模型
3、 关系数据库的关键特性包括完善的事务机制和高效的查询机制。但是,关系数据库引以为傲的两个关键特性,到了Web2.0时代却成了鸡肋,主要表现在以下几个方面:
(1) Web2.0网站系统通常不要求严格的数据库事务
(2) Web2.0并不要求严格的读写实时性
(3) Web2.0通常不包含大量复杂的SQL查询(去结构化,存储空间换取更好的查询性能)
4, 对网页的访问,每次都去读取数据库吗。以前使用的是动态网页静态化。面对高并发的情况无能为力。实时生成的数据对数据库的负载非常高。
>比如大公司的MySql集群。
>
>一开使只有一台服务器,数据多了之后采用主从模式,Master/Slave
>
>主服务器的数据通过同步或异步的方式将数据更新到备服务器当中。
>
>这样写负载到主服务器,读负载到备服务器中,实现读写负载分离。但这样也就只有两个服务器,中大型公司还是不够用。
>
>所以出现了分库,分表。但是麻烦。总结:关系型数据库在web2.0时代不大行啊。
NoSQL与关系数据库的比较
| 比较标准 | RDBMS | NoSQL | 备注 |
|---|---|---|---|
| 数据库原理 | 完全支持 | 部分支持 | RDBMS有关系代数理论作为基础 。NoSQL没有统一的理论基础 |
| 数据规模 | 大 | 超大 | RDBMS很难实现横向扩展, 纵向扩展的空间也比较有限, 性能 会随着数据规模的增大而降低。 NoSQL可以很容易通过添加更多设备来支持更大规模的数据 |
| 数据库模式 | 固定 | 灵活 | RDBMS需要定义数据库模式, 严格遵守数据定义和相关约束条 件。 NoSQL不存在数据库模式, 可以自由灵活定义并存储各种不同 类型的数据 |
| 查询效率 | 快 | 可以实现高效的简单 查询,但是不具备高 度结构化查询等特性, 复杂查询的性能不尽 人意 | RDBMS借助于索引机制可以实现快速查询(包括记录查询和范 围查询) 。很多NoSQL数据库没有面向复杂查询的索引, 虽然NoSQL可以 使用MapReduce来加速查询, 但是, 在复杂查询方面的性能仍 然不如RDBMS |
| 比较标准 | RDBMS | NoSQL | 备注 |
|---|---|---|---|
| 一致性 | 强一致性 | 弱一致性 | RDBMS严格遵守事务ACID模型, 可以保证事务强一致性 很多NoSQL数据库放松了对事务ACID四性的要求, 而是遵守 BASE模型, 只能保证最终一致性 |
| 数据完整性 | 容易实现 | 很难实现 | 任何一个RDBMS都可以很容易实现数据完整性, 比如通过主键 或者非空约束来实现实体完整性, 通过主键、 外键来实现参照 完整性, 通过约束或者触发器来实现用户自定义完整性 但是, 在NoSQL数据库却无法实现 |
| 扩展性 | 一般 | 好 | RDBMS很难实现横向扩展, 纵向扩展的空间也比较有限 NoSQL在设计之初就充分考虑了横向扩展的需求, 可以很容易 通过添加廉价设备实现扩展 |
| 可用性 | 好 | 很好 | RDBMS在任何时候都以保证数据一致性为优先目标, 其次才是 优化系统性能, 随着数据规模的增大, RDBMS为了保证严格的 一致性, 只能提供相对较弱的可用性 大多数NoSQL都能提供较高的可用性 |
| 比较标准 | RDBMS | NoSQL | 备注 |
|---|---|---|---|
| 标准化 | 是 | 否 | RDBMS已经标准化(SQL) NoSQL还没有行业标准, 不同的NoSQL数据库都有自己的查询 语言, 很难规范应用程序接口 StoneBraker认为: NoSQL缺乏统一查询语言, 将会拖慢NoSQL 发展 |
| 技术支持 | 高 | 低 | RDBMS经过几十年的发展, 已经非常成熟, Oracle等大型厂商 都可以提供很好的技术支持 NoSQL在技术支持方面仍然处于起步阶段, 还不成熟, 缺乏有 力的技术支持 |
| 可维护性 | 复杂 | 复杂 | RDBMS需要专门的数据库管理员(DBA)维护 NoSQL数据库虽然没有DBMS复杂, 也难以维护 |
总结
(1)关系数据库
优势:以完善的关系代数理论作为基础,有严格的标准,支持事务ACID四性,借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持劣势:可扩展性较差,无法较好支持海量数据存储,数据模型过于死板、无法较好支持Web2.0应用,事务机制影响了系统的整体性能等
(2) NoSQL数据库
优势:可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力等劣势:缺乏数学理论基础,复杂查询性能不高,大都不能实现务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等
关系数据库和NoSQL数据库各有优缺点,彼此无法取代
•关系数据库应用场景:电信、银行等领域的关键业务系统,需要保证强事务一致性
•NoSQL数据库应用场景:互联网企业、传统企业的非关键业务(比如数据分析)
采用混合架构
•案例:亚马逊公司就使用不同类型的数据库来支撑它的电子商务应用
•对于“购物篮”这种临时性数据,采用键值存储会更加高效
•当前的产品和订单信息则适合存放在关系数据库中
•大量的历史订单信息则适合保存在类似MongoDB的文档数据库中
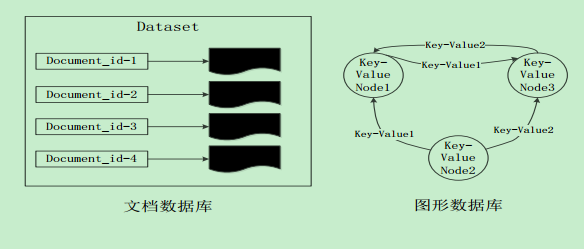
四大类型

键值数据库
| 相关产品 | Redis、 Riak、 SimpleDB、 Chordless、 Scalaris、 Memcached |
|---|---|
| 数据模型 | 键/值对 键是一个字符串对象 值可以是任意类型的数据,比如整型、字符型、数组、列表、集合等 |
| 典型应用 | 涉及频繁读写、拥有简单数据模型的应用 内容缓存,比如会话、配置文件、参数、购物车等 存储配置和用户数据信息的移动应用 |
| 优点 | 扩展性好,灵活性好,大量写操作时性能高 |
| 缺点 | 无法存储结构化信息,条件查询效率较低 |
| 不适用情形 | 不是通过键而是通过值来查:键值数据库根本没有通过值查询的途径 需要存储数据之间的关系:在键值数据库中,不能通过两个或两个以上的键来关联数据 需要事务的支持:在一些键值数据库中,产生故障时,不可以回滚 |
| 使用者 | 百度云数据库(Redis)、 GitHub(Riak)、 BestBuy(Riak)、 Twitter(Redis和Memcached)、 StackOverFlow(Redis)、 Instagram (Redis)、 Youtube(Memcached)、 Wikipedia (Memcached) |
Redis有时候会被人们称为“强化版的Memcached” 支持持久化、数据恢复、更多数据类型
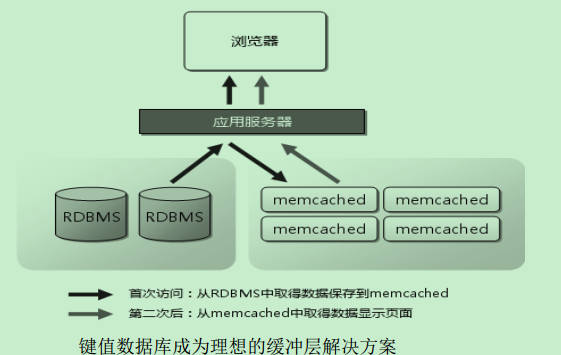
总结:
不擅长通过值来查找。
实际应用中作为缓冲层。
列族数据库
| 相关产品 | BigTable、 HBase、 Cassandra、 HadoopDB、 GreenPlum、 PNUTS |
|---|---|
| 数据模型 | 列族 |
| 典型应用 | 分布式数据存储与管理 数据在地理上分布于多个数据中心的应用程序 可以容忍副本中存在短期不一致情况的应用程序 拥有动态字段的应用程序 拥有潜在大量数据的应用程序,大到几百TB的数据 |
| 优点 | 查找速度快,可扩展性强,容易进行分布式扩展,复杂性低 |
| 缺点 | 功能较少, 大都不支持强事务一致性 |
| 不适用情形 | 需要ACID事务支持的情形, Cassandra等产品就不适用 |
| 使用者 | Ebay(Cassandra)、 Instagram(Cassandra)、 NASA(Cassandra)、 Twitter (Cassandra and HBase)、 Facebook(HBase)、 Yahoo!(HBase) |
文档数据库
“文档”其实是一个数据记录,这个记录能够对包含的数据类型和内容进行“自我描述”。 XML文档、 HTML文档和JSON 文档就属于这一类。
SequoiaDB就是使用JSON格式的文档数据库,它的存储的数据是这样的:
•数据是不规则的,每一条记录包含了所有的有关“SequoiaDB”的信息而没有任何外部的引用,这条记录就是“自包含”的
•这使得记录很容易完全移动到其他服务器,因为这条记录的所有信息都包含在里面了,不需要考虑还有信息在别的表没有一起迁移走
•同时,因为在移动过程中,只有被移动的那一条记录(文档)需要操作,而不像关系型中每个有关联的表都需要锁住来保证一致性,这样一来ACID的保证就会变得更快速,读写的速度也会有很大的提升
| 相关产品 | MongoDB、 CouchDB、 Terrastore、 ThruDB、 RavenDB、 SisoDB、 RaptorDB、 CloudKit、 Perservere、 Jackrabbit |
|---|---|
| 数据模型 | 键/值 值(value)是版本化的文档 |
| 典型应用 | 存储、索引并管理面向文档的数据或者类似的半结构化数据 比如,用于后台具有大量读写操作的网站、使用JSON数据结构的应用、使用嵌套结 构等非规范化数据的应用程序 |
| 优点 | 性能好(高并发) ,灵活性高,复杂性低,数据结构灵活 提供嵌入式文档功能,将经常查询的数据存储在同一个文档中 既可以根据键来构建索引,也可以根据内容构建索引 |
| 缺点 | 缺乏统一的查询语法 |
| 不适用情形 | 在不同的文档上添加事务。文档数据库并不支持文档间的事务,如果对这方面有需求 则不应该选用这个解决方案 |
| 使用者 | 百度云数据库(MongoDB)、 SAP(MongoDB)、 Codecademy (MongoDB)、 Foursquare (MongoDB)、 NBC News (RavenDB) |
总结:
自描述
图形数据库
| 相关产品 | Neo4J、 OrientDB、 InfoGrid、 Infinite Graph、 GraphDB |
|---|---|
| 数据模型 | 图结构 |
| 典型应用 | 专门用于处理具有高度相互关联关系的数据,比较适合于社交网络、模式识别、依赖 分析、推荐系统以及路径寻找等问题 |
| 优点 | 灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱 |
| 缺点 | 复杂性高,只能支持一定的数据规模 |
| 使用者 | Adobe(Neo4J)、 Cisco(Neo4J)、 T-Mobile(Neo4J) |
•MySQL产生年代较早,而且随着LAMP大潮得以成熟。尽管其没有什么大的改进,但是新兴的互联网使用的最多的数据库
•MongoDB是个新生事物,提供更灵活的数据模型、异步提交、地理位置索引等五花十色的功能
•HBase是个“仗势欺人”的大象兵。依仗着Hadoop的生态环境,可以有很好的扩展性。但是就像象兵一样,使用者需要养一头大象(Hadoop),才能驱使他
•Redis是键值存储的代表,功能最简单。提供随机数据存储。就像一根棒子一样,没有多余的构造。但是也正是因此,它的伸缩性特别好。就像悟空手里的金箍棒,大可捅破天,小能成缩成针
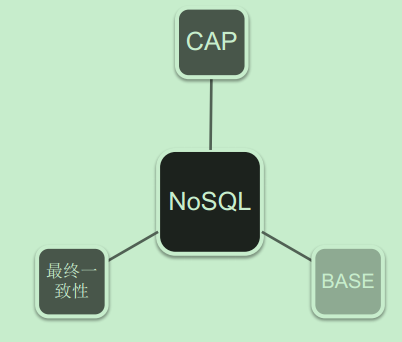
三大基石
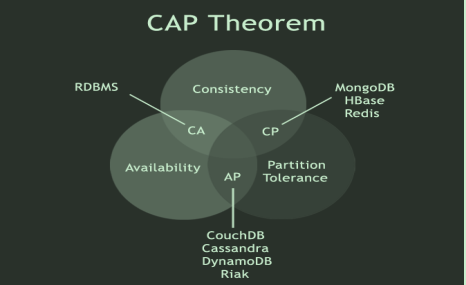
CAP:分布式架构的重要特性
什么是cap
C(Consistency): 一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的,或者说,所有节点在同一时间具有相同的数据
A:(Availability): 可用性,是指快速获取数据,可以在确定的时间内返回操作结果,保证每个请求不管成功或者失败都有响应;
P(Tolerance of Network Partition): 分区容忍性,是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行,也就是说,系统中任意信息的丢失或失败不会影响系统的继续运作
CAP理论告诉我们,一个分布式系统不可能同时满足一致性、可用性和分区容忍性这三个需求,最多只能同时满足其中两个,正所谓“鱼和熊掌不可兼得”。
一个牺牲一致性来换取可用性的实例
(a)初始状态
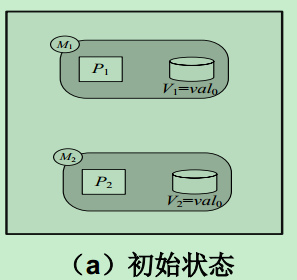
(b)正常执行过程
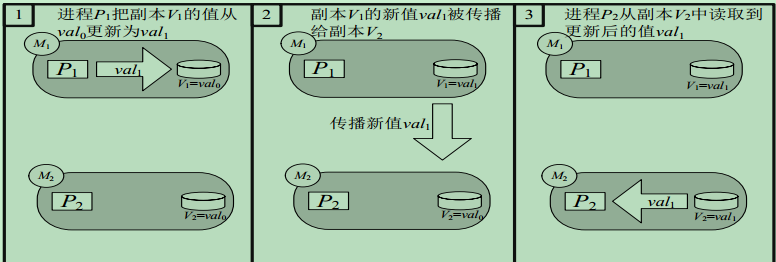
(c) 更新传播失败时的执行过程
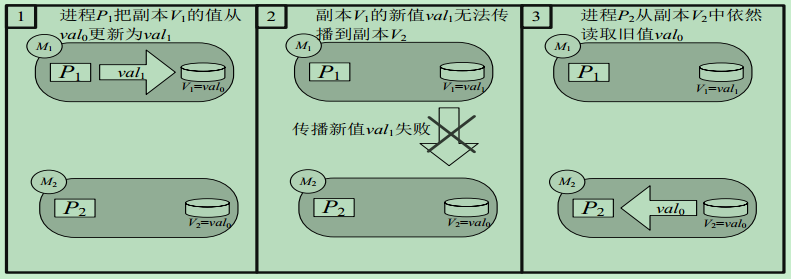
当处理CAP的问题时,可以有几个明显的选择:
1.CA:也就是强调一致性(C)和可用性(A),放弃分区容忍性(P),最简单的做法是把所有与事务相关的内容都放到同一台机器上。很显然,这种做法会严重影响系统的可扩展性。传统的关系数据库(MySQL、 SQL Server和PostgreSQL),都采用了这种设计原则,因此,扩展性都比较差
2.CP:也就是强调一致性(C)和分区容忍性(P),放弃可用性(A),当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务
3.AP:也就是强调可用性(A)和分区容忍性(P),放弃一致性(C),允许系统返回不一致的数据
不同产品在CAP理论下的不同设计原则
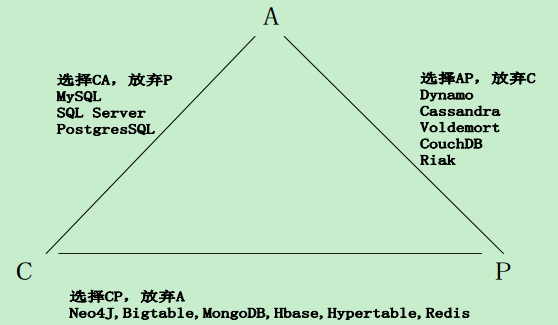
总结:传统的关系型数据库都是放弃分区容忍性,而保证一致性与可用性。
分布式数据库:大部分NoSql,如Redis,MogoDB是放弃可用性,而保证一致性与分区容忍性
BASE
Basically Availble, Soft-state, Eventual consistency
先看ACID :
一个数据库事务具有ACID四性:
- A(Atomicity):原子性,是指事务必须是原子工作单元,对于其数据修改,要么全都执行,要么全都不执行
- C(Consistency):一致性,是指事务在完成时,必须使所有的数据都保持一致状态
- I(Isolation):隔离性,是指由并发事务所做的修改必须与任何其它并发事务所做的修改隔离
- D(Durability):持久性,是指事务完成之后,它对于系统的影响是永久性的,该修改即使出现致命的系统故障也将一直保持
再看BASE:
BASE的基本含义是基本可用(Basically Availble)、软状态(Soft-state)和最终一致性(Eventual consistency)
基本可用
基本可用,是指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现软状态
“软状态(soft-state)”是与“硬状态(hard-state)”相对应的一种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同步,具有一定的滞后性最终一致性
一致性的类型包括强一致性和弱一致性,二者的主要区别在于高并发的数据访问操作下,后续操作是否能够获取最新的数据。对于强一致性而言,当执行完一次更新操作后,后续的其他读操作就可以保证读到更新后的最新数据;反之,如果不能保证后续访问读到的都是更新后的最新数据,那么就是弱一致性。
而最终一致性只不过是弱一致性的一种特例,允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,必须最终读到更新后的数据。
最常见的实现最终一致性的系统是DNS(域名系统)。一个域名更新操作根据配置的形式被分发出去,并结合有过期机制的缓存;最终所有的客户端可以看到最新的值
| ACID | BASE |
|---|---|
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) | 无 |
总结:
BASE:碱
ACID:酸
最终一致性
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
- 因果一致性:如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将获得A写入的最新值。而与进程A无因果关系的进程C的访问,仍然遵守一般的最终一致性规则
- “读己之所写”一致性:可以视为因果一致性的一个特例。当进程A自己执行一个更新操作之后,它自己总是可以访问到更新过的值,绝不会看到旧值
- 单调读一致性:如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值
- 会话一致性:它把访问存储系统的进程放到会话(session)的上下文中,只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话
- 单调写一致性:系统保证来自同一个进程的写操作顺序执行。系统必须保证这种程度的一致性,否则就非常难以编程了
如何实现各种类型的一致性?
对于分布式数据系统:
•N — 数据复制的份数
•W — 更新数据是需要保证写完成的节点数
•R — 读取数据的时候需要读取的节点数
如果W+R>N,写的节点和读的节点重叠,则是强一致性。例如对于典型的一主一备同步复制的关系型数据库, N=2,W=2,R=1,则不管读的是主库还是备库的数据,都是一致的。一般设定是R+W = N+1,这是保证强一致性的最小设定
如果W+R<=N,则是弱一致性。例如对于一主一备异步复制的关系型数据库,N=2,W=1,R=1,则如果读的是备库,就可能无法读取主库已经更新过的数据,所以是弱一致性。
对于分布式系统,为了保证高可用性,一般设置N>=3。不同的N,W,R组合,是在可用性和一致性之间取一个平衡,以适应不同的应用场景。
•如果N=W,R=1,任何一个写节点失效,都会导致写失败,因此可用性会降低,但是由于数据分布的N个节点是同步写入的,因此可以保证强一致性。
实例: HBase是借助其底层的HDFS来实现其数据冗余备份的。 HDFS采用的就是强一致性保证。在数据没有完全同步到N个节点前,写操作是不会返回成功的。也就是说它的W=N,而读操作只需要读到一个值即可,也就是说它R=1。
•像Voldemort, Cassandra和Riak这些类Dynamo的系统,通常都允许用户按需要设置N, R, W三个值,即使是设置成W+R<= N也是可以的。也就是说他允许用户在强一致性和最终一致性之间自由选择。而在用户选择了最终一致性,或者是W<N的强一致性时,则总会出现一段“各个节点数据不同步导致系统处理不一致的时间”。为了提供最终一致性的支持,这些系统会提供一些工具来使数据更新被最终同步到所有相关节点。
从NoSQL到NewSQL数据库
大数据引发数据处理架构变革 :
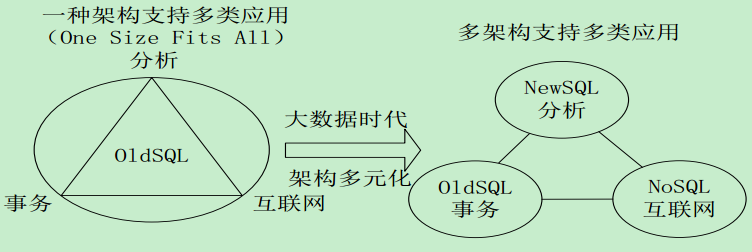
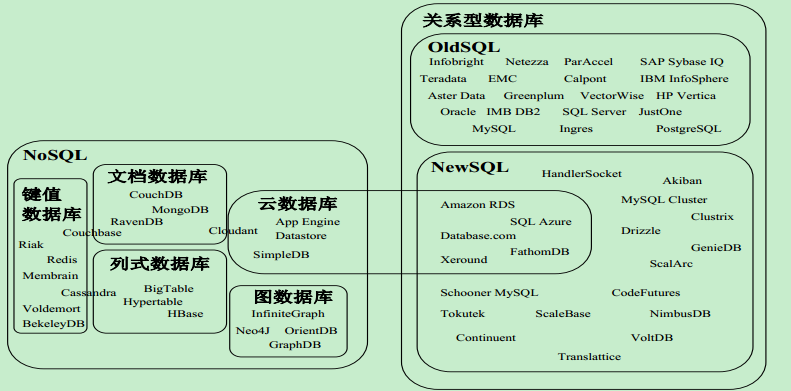
关系数据库、 NoSQL和NewSQL数据库产品分类图 :
文档数据库MongoDB
MongoDB指南:
http://www.runoob.com/mongodb/mongodb-tutorial.html
http://dblab.xmu.edu.cn/blog/115/
•MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
•在高负载的情况下,添加更多的节点,可以保证服务器性能。
•MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
•MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。

主要特点 :
•提供了一个面向文档存储,操作起来比较简单和容易
•可以设置任何属性的索引来实现更快的排序
•具有较好的水平可扩展性
•支持丰富的查询表达式,可轻易查询文档中内嵌的对象及数组
•可以实现替换完成的文档(数据)或者一些指定的数据字段
•MongoDB中的Map/Reduce主要是用来对数据进行批量处理和聚合操作
•支持各种编程语言:RUBY, PYTHON, JAVA, C++, PHP, C#等语言
•MongoDB安装简单
在mongodb中基本的概念是文档、集合、数据库 :
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id 字段设置为主键 |
一个实例:
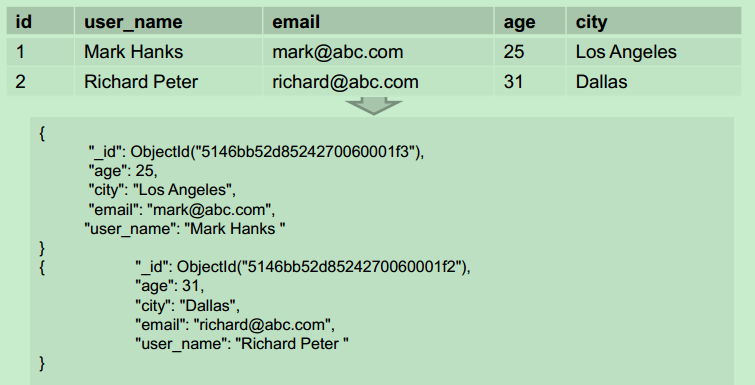
在一个关系型数据库中,一篇博客(包含文章内容、评论、评论的投票)会被打散在多张数据表中。在文档数据库MongoDB中,能用一个文档来表示一篇博客, 评论与投票作为文档数组,放在正文主文档中。这样数据更易于管
理,消除了传统关系型数据库中影响性能和水平扩展性的“JOIN”操作。
数据库
•一个mongodb中可以建立多个数据库。
•MongoDB的默认数据库为”db”,该数据库存储在data目录中。
•MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
文档
文档是一个键值(key-value)对(即BSON)。 MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。一个简单的文档例子如下:
{“site” :“haha.cn” , “name” :“哈哈”}
下表列出了 RDBMS 与 MongoDB 对应的术语:
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
| 数据库服务和客户端 | |
|---|---|
| Mysqld/Oracle | mongod |
| mysql/sqlplus | mongo |
集合
•集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
•集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
比如,我们可以将以下不同数据结构的文档插入到集合中:
{“site”:”www.baidu.com“}
{“site” :“dblab.xmu.edu.cn” , “name” :“厦门大学数据库实验室”}
{“site”:”www.runoob.com","name":"菜鸟教程","num":5}
MongoDB 数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中, UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Arrays | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
安装使用
启动 MongoDB服务只需要在MongoDB安装目录的bin目录下执行’mongod’即可
使用 MongoDB shell访问MongoDB
mongodb://localhost
•使用 MongoDB shell 来连接 MongoDB 服务器
•使用用户名和密码连接登陆到指定数据库:
mongodb://admin:123456@localhost/testMongoDB 创建数据库
MongoDB 创建数据库的语法格式如下:
use DATABASE_NAME
如果数据库不存在,则创建数据库,否则切换到指定数据库。
如果你想查看所有数据库,可以使用 show dbs 命令创建集合
MongoDB没有单独创建集合名的shell命令,在插入数据的时候,
MongoDB会自动创建对应的集合。**MongoDB 插入文档 **
文档的数据结构和JSON基本一样。
所有存储在集合中的数据都是BSON格式。
BSON是一种类JSON的一种二进制形式的存储格式,简称Binary JSON。
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:db.COLLECTION_NAME.insert(document)
使用Java程序访问 MongoDB
环境配置
•在Java程序中如果要使用MongoDB,需要确保已经安装了Java环境及MongoDB JDBC 驱动。
•首先必须下载mongo jar包,下载地址:https://github.com/mongodb/mongo-java-driver/downloads, 请确保下载最新版本。
•需要将mongo.jar包含在你的 classpath 中
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
>import com.mongodb.MongoClient;
>……//这里省略其他需要导入的包
>public class MongoDBJDBC{
>public static void main( String args[] ){
>try{
// 连接到 mongodb 服务
MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
// 连接到数据库
DB db = mongoClient.getDB( "test" );
System.out.println("Connect to database successfully");
boolean auth = db.authenticate(myUserName, myPassword);
System.out.println("Authentication: "+auth);
}catch(Exception e){
System.err.println( e.getClass().getName() + ": " + e.getMessage() );
}
}
>}
>(2)创建集合 可以使用com.mongodb.DB类中的createCollection()来创建集合
>public class MongoDBJDBC{
>public static void main( String args[] ){
>try{
>// 连接到 mongodb 服务
>MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
>// 连接到数据库
>DB db = mongoClient.getDB( "test" );
>System.out.println("Connect to database successfully");
>boolean auth = db.authenticate(myUserName, myPassword);
>System.out.println("Authentication: "+auth);
>DBCollection coll = db.createCollection("mycol");
>System.out.println("Collection created successfully");
>}catch(Exception e){
>System.err.println( e.getClass().getName() + ": " + e.getMessage() );
>}
>}
>}
>(3)插入文档 可以使用com.mongodb.DBCollection类的 insert() 方法来插入一个文档
>public class MongoDBJDBC{
>public static void main( String args[] ){
>try{ // 连接到 mongodb 服务
>MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
>DB db = mongoClient.getDB( "test" ); // 连接到数据库
>System.out.println("Connect to database successfully");
>boolean auth = db.authenticate(myUserName, myPassword);
>System.out.println("Authentication: "+auth);
>DBCollection coll = db.getCollection("mycol");
>System.out.println("Collection mycol selected successfully");
>BasicDBObject doc = new BasicDBObject("title", "MongoDB").
>append("description", "database").
>append("likes", 100).
>append("url", "`http://www.w3cschool.cc/mongodb/`").
>append("by", "w3cschool.cc");
>coll.insert(doc);
>System.out.println("Document inserted successfully");
>}catch(Exception e){
>System.err.println( e.getClass().getName() + ": " + e.getMessage() );
>}
>}
>}
云数据库
MapReduce
概述
分布式并行编程
•“摩尔定律”, CPU性能大约每隔18个月翻一番
•从2005年开始摩尔定律逐渐失效 ,需要处理的数据量快速增加,人们开始借助于分布式并行编程来提高程序性能
•分布式程序运行在大规模计算机集群上,可以并行执行大规模数据处理任务,从而获得海量的计算能力
•谷歌公司最先提出了分布式并行编程模型MapReduce, Hadoop MapReduce是它的开源实现,后者比前者使用门槛低很多问题:在MapReduce出现之前,已经有像MPI这样非常成熟的并行计算框架了,那么为什么Google还需要MapReduce? MapReduce相较于传统的并行计算框架有什么优势?
传统并行计算框架 MapReduce 集群架构/容错性 共享式(共享内存/共享存储),容错性差 非共享式,容错性好 硬件/价格/扩展性 刀片服务器、高速网、 SAN,价格贵, 扩展性差 普通PC机,便宜,扩展性好 编程/学习难度 what-how,难 what,简单 适用场景 实时、细粒度计算、计算密集型 批处理、非实时、数据密集型
MapReduce模型简介
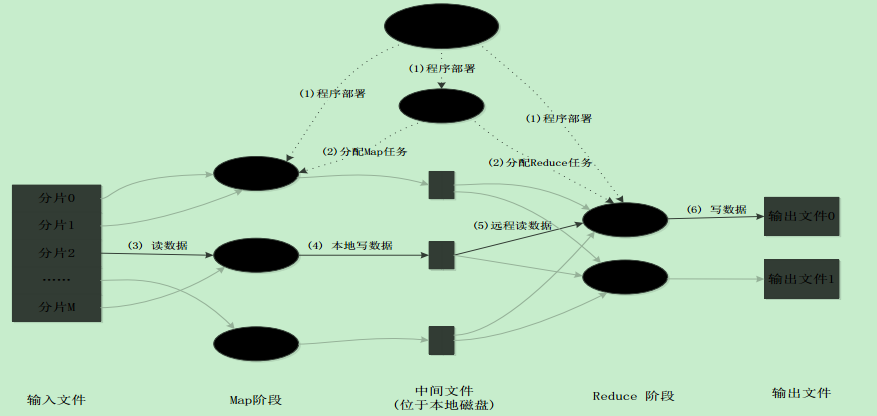
•MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数: Map和Reduce
•编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算
•MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
•MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销
•MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker, Slave上运行TaskTracker
•Hadoop框架是用Java实现的,但是, MapReduce应用程序则不一定要用Java来写
Map和Reduce函数
| 函数 | 输入 | 输出 | 说明 |
|---|---|---|---|
| Map | <k1,v1> 如: <行号,”a b c”> | List(<k2,v2>) 如: <“a”,1> <“b”,1> <“c”,1> | 1.将小数据集进一步解析成一批 <key,value>对,输入Map函数中进行处理 2.每一个输入的<k1,v1>会输出一批<k2,v2> 。 <k 2,v2>是计算的中间结果 |
| Reduce | <k 2,List(v2)> 如: <“a”,<1,1,1>> | <k 3,v3> <“a”,3> | 输入的中间结果<k2,List(v2)>中的List(v2) 表示是一批属于同一个k2的value |
MapReduce体系结构
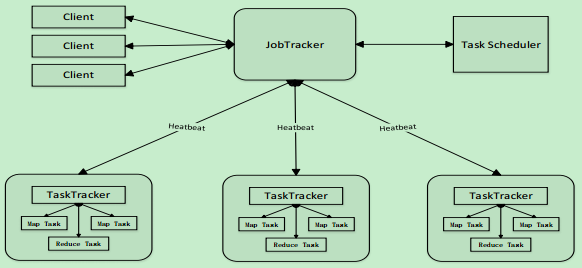
MapReduce体系结构主要由四个部分组成,分别是: Client、 JobTracker、TaskTracker以及Task
1) Client
•用户编写的MapReduce程序通过Client提交到JobTracker端
•用户可通过Client提供的一些接口查看作业运行状态2) JobTracker
•JobTracker负责资源监控和作业调度
•JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
•JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源3) TaskTracker
•TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
•TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。 slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task使用4) Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
MapReduce工作流程
工作流程概述
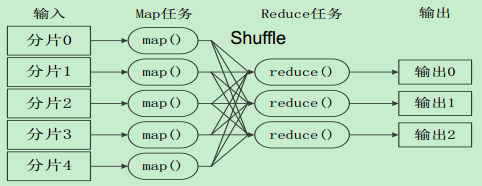
•不同的Map任务之间不会进行通信
•不同的Reduce任务之间也不会发生任何信息交换
•用户不能显式地从一台机器向另一台机器发送消息
•所有的数据交换都是通过MapReduce框架自身去实现的
MapReduce各个执行阶段
关于Split(分片)
HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。 split 是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
Map任务的数量
•Hadoop为每个split创建一个Map任务, split 的多少决定了Map任务的数目。大多数情况下,理想的分片大小是一个HDFS块
Reduce任务的数量
•最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目
•通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(这样可
以预留一些系统资源处理可能发生的错误)
Shuffle过程详解
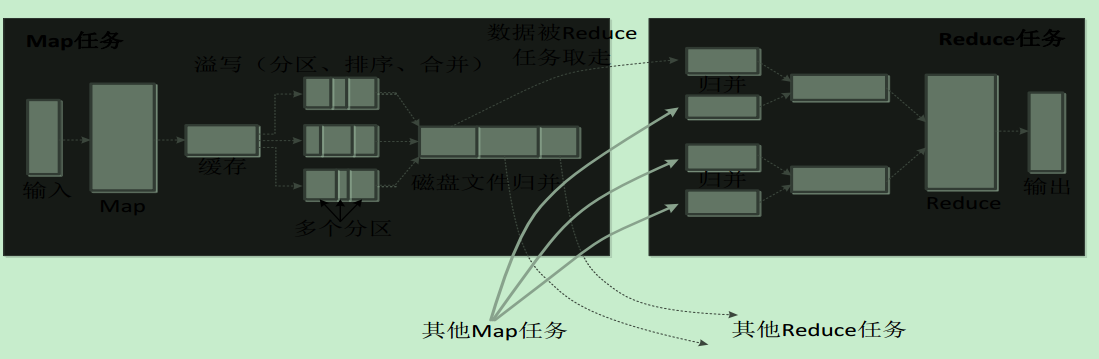
map端的shuffle
•每个Map任务分配一个缓存
•MapReduce默认100MB缓存
•设置溢写比例0.8
•分区默认采用哈希函数
•排序是默认的操作
•排序后可以合并(Combine)
•合并不能改变最终结果
•在Map任务全部结束之前进行归并
•归并得到一个大的文件,放在本地磁盘
•文件归并时,如果溢写文件数量大于预定值(默认是3)则可以再次启动Combiner,少于3不需要
•JobTracker会一直监测Map任务的执行,并通知Reduce任务来领取数据合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
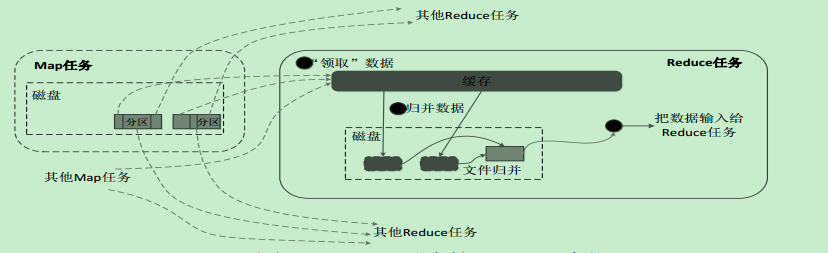
Reduce端的Shuffle过程
•Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则领取数据
•Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘
•多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
•当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
MapReduce应用程序执行过程
实例分析: WordCount
WordCount程序任务
任务
| 程序 | WordCount |
|---|---|
| 输入 | 一个包含大量单词的文本文件 |
| 输出 | 文件中每个单词及其出现次数(频数),并按照单词字母顺序排序,每 个单词和其频数占一行,单词和频数之间有间隔 |
| 输入 | 输出 |
|---|---|
| Hello World Hello Hadoop Hello MapReduce | Hadoop 1 Hello 3 MapReduce 1 World 1 |
WordCount设计思路
• 首先,需要检查WordCount程序任务是否可以采用MapReduce来实现
• 其次,确定MapReduce程序的设计思路
• 最后,确定MapReduce程序的执行过程
一个WordCount执行过程的实例
Map过程示意图 :

• 分组与聚合运算
• 矩阵-向量乘法
• 矩阵乘法
用MapReduce实现关系的自然连接

• 假设有关系R(A, B)和S(B,C),对二者进行自然连接操作
• 使用Map过程,把来自R的每个元组<a,b>转换成一个键值对<b, <R,a>>,其中的键就是属性B的值。把关系R包含到值中,这样做使得我们可以在Reduce阶段,只把那些来自R的元组和来自S的元组进行匹配。类似地,使用Map过程,把来自S的每个元组<b,c>,转换成一个键值对<b,<S,c>>
• 所有具有相同B值的元组被发送到同一个Reduce进程中, Reduce进程的任务是,把来自关系R和S的、具有相同属性B值的元组进行合并
• Reduce进程的输出则是连接后的元组<a,b,c>,输出被写到一个单独的输出文件中

MapReduce编程实践
任务:

http://dblab.xmu.edu.cn/blog/631-2/
数据仓库Hive
概述
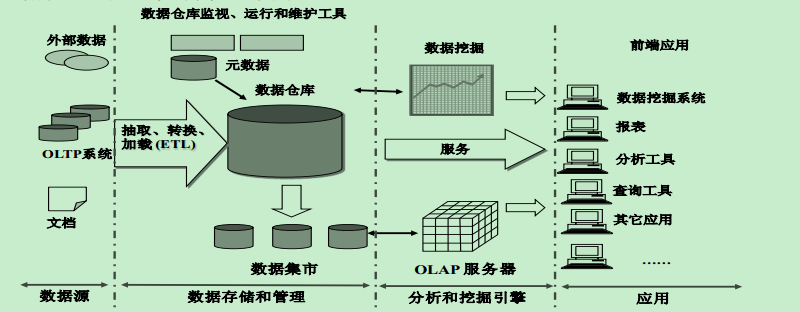
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
传统数据仓库面临的挑战
(1)无法满足快速增长的海量数据存储需求
(2)无法有效处理不同类型的数据
(3) 计算和处理能力不足
Hive简介
•Hive是一个构建于Hadoop顶层的数据仓库工具
•支持大规模数据存储、分析,具有良好的可扩展性
•某种程度上可以看作是用户编程接口,本身不存储和处理数据
•依赖分布式文件系统HDFS存储数据
•依赖分布式并行计算模型MapReduce处理数据
•定义了简单的类似SQL的查询语言——HiveQL
•用户可以通过编写的HiveQL语句运行MapReduce任务
•可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上
•是一个可以提供有效、合理、直观组织和使用数据的分析工具
Hive具有的特点非常适用于数据仓库
•采用批处理方式处理海量数据
•Hive需要把HiveQL语句转换成MapReduce任务进行运行
•数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化
•提供适合数据仓库操作的工具
•Hive本身提供了一系列对数据进行提取、转换、加载(ETL)的工具,可以存储、查询和分析存储在Hadoop中的大规模数据
•这些工具能够很好地满足数据仓库各种应用场景
Hive与Hadoop生态系统中其他组件的关系
•Hive依赖于HDFS 存储数据
•Hive依赖于MapReduce 处理数据
•在某些场景下Pig可以作为Hive的替代工具
•HBase 提供数据的实时访问
Hive与传统数据库的对比分析
• Hive在很多方面和传统的关系数据库类似,但是它的底层依赖的是HDFS和MapReduce,所以在很多方面又有别于传统数据库
对比项目 Hive 传统数据库 数据插入 支持批量导入 支持单条和批量导入 数据更新 不支持 支持 索引 支持 支持 分区 支持 支持 执行延迟 高 低 扩展性 好 有限
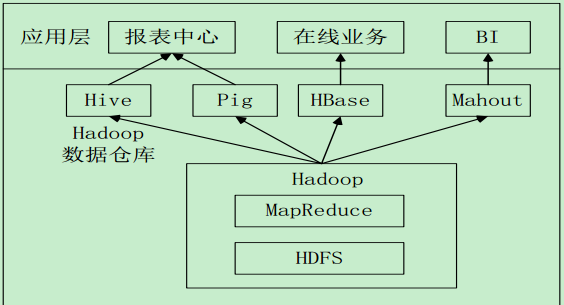
Hive在企业中的部署和应用
Hive系统架构
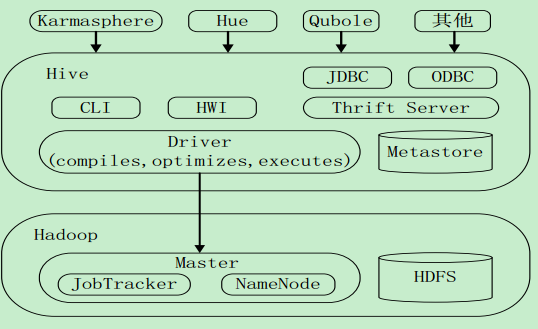
•用户接口模块包括CLI、HWI、 JDBC、 ODBC、Thrift Server
•驱动模块(Driver)包括编译器、优化器、执行器等,负责把HiveSQL语句转换成一系列MapReduce作业
•元数据存储模块(Metastore)是一个独立的关系型数据库(自带derby数据 库,或MySQL数据库)
Hive工作原理
SQL语句转换成MapReduce作业的基本原理
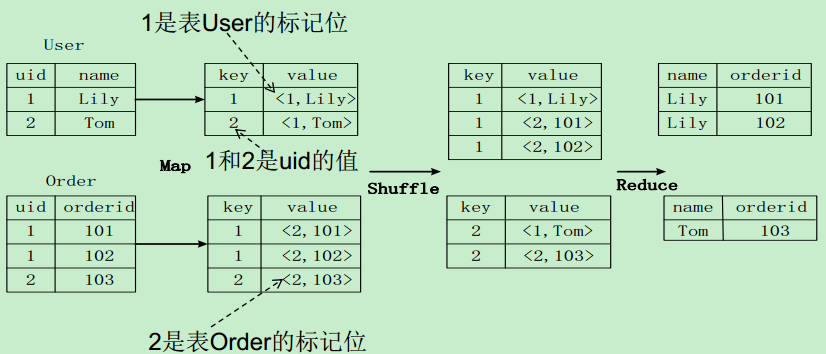
join的实现原理
group by的实现原理
存在一个分组(Group By)操作,其功能是把表Score的不同片段按照rank和level的组合值进行合并,计算不同rank和level的组合值分别有几条记录:select rank, level ,count(*) as value from score group by rank, level
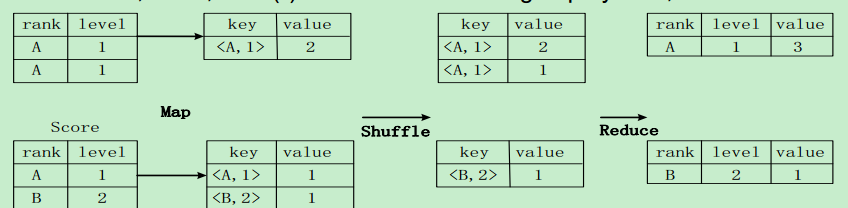
Hive中SQL查询转换成MapReduce作业的过程
•当用户向Hive输入一段命令或查询时, Hive需要与Hadoop交互工作来完成该操作:
•驱动模块接收该命令或查询编译器
•对该命令或查询进行解析编译
•由优化器对该命令或查询进行优化计算
•该命令或查询通过执行器进行执行
第1步:由Hive驱动模块中的编译器对用户输入的SQL语言进行词法和语法解析,将SQL语句转
化为抽象语法树的形式
第2步: 抽象语法树的结构仍很复杂,不方便直接翻译为MapReduce算法程序,因此,把抽象
语法书转化为查询块
第3步:把查询块转换成逻辑查询计划,里面包含了许多逻辑操作符
第4步:重写逻辑查询计划,进行优化,合并多余操作,减少MapReduce任务数量
第5步:将逻辑操作符转换成需要执行的具体MapReduce任务
第6步:对生成的MapReduce任务进行优化,生成最终的MapReduce任务执行计划
第7步:由Hive驱动模块中的执行器,对最终的MapReduce任务进行执行输出几点说明:
• 当启动MapReduce程序时, Hive本身是不会生成MapReduce算法程序的
• 需要通过一个表示“Job执行计划”的XML文件驱动执行内置的、原生的Mapper和Reducer模块
• Hive通过和JobTracker通信来初始化MapReduce任务,不必直接部署在JobTracker所在的管理节点上执行
• 通常在大型集群上,会有专门的网关机来部署Hive工具。网关机的作用主要是远程操作和管理节点上的JobTracker通信来执行任务
• 数据文件通常存储在HDFS上, HDFS由名称节点管理
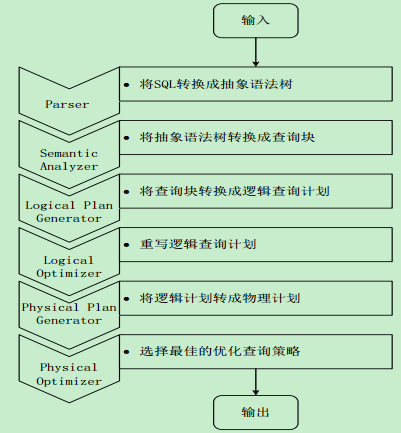
Hive HA基本原理
问题: 在实际应用中, Hive也暴露出不稳定的问题
解决方案: Hive HA(High Availability)
•由多个Hive实例进行管理的,这些Hive实例被纳入到一个资源池中,并由HAProxy提供一个统一的对外接口
•对于程序开发人员来说,可以把它认为是一台超强“Hive”
Impala
Impala简介
• Impala是由Cloudera公司开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase上的PB级大数据, 在性能上比Hive高出3~30倍
• Impala的运行需要依赖于Hive的元数据
• Impala是参照 Dremel系统进行设计的
• Impala采用了与商用并行关系数据库类似的分布式查询引擎,可以直接与HDFS和HBase进行交互查询
• Impala和Hive采用相同的SQL语法、 ODBC驱动程序和用户接口Impala与其他组件关系 :
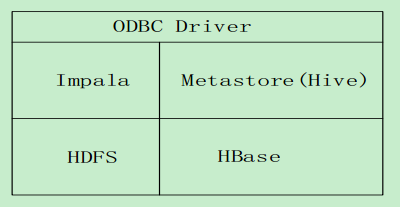
Impala系统架构
Impala和Hive、 HDFS、 HBase等工具是统一部署在一个Hadoop平台上的Impala主要由Impalad, State Store和CLI三部分组成
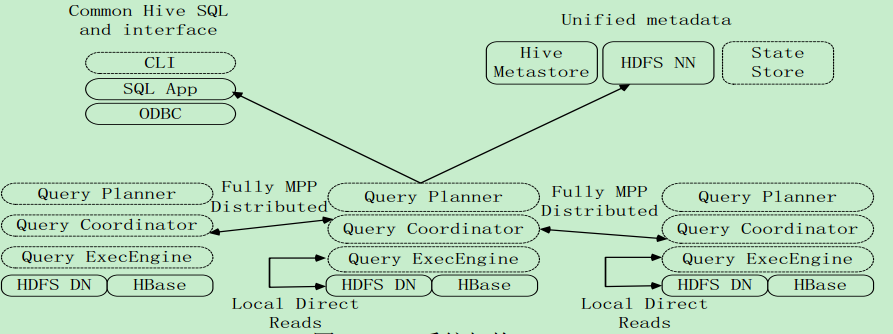
Impala主要由Impalad, State Store和CLI三部分组成 :
- Impalad
• 负责协调客户端提交的查询的执行
• 包含Query Planner、 Query Coordinator和Query Exec Engine三个模块
• 与HDFS的数据节点(HDFS DN)运行在同一节点上
• 给其他Impalad分配任务以及收集其他Impalad的执行结果进行汇总
• Impalad也会执行其他Impalad给其分配的任务,主要就是对本地HDFS和HBase里的部分数据进- State Store
• 会创建一个statestored进程
• 负责收集分布在集群中各个Impalad进程的资源信息,用于查询调度- CLI
• 给用户提供查询使用的命令行工具
• 还提供了Hue、 JDBC及ODBC的使用接口说明: Impala中的元数据直接存储在Hive中。 Impala采用与Hive相同的元数据、 SQL语法、 ODBC驱动程序和用户接口,从而使得在一个Hadoop平台上,可以统一部署Hive和Impala等分析工具,同时支持批处理和实时查询
Impala查询执行过程
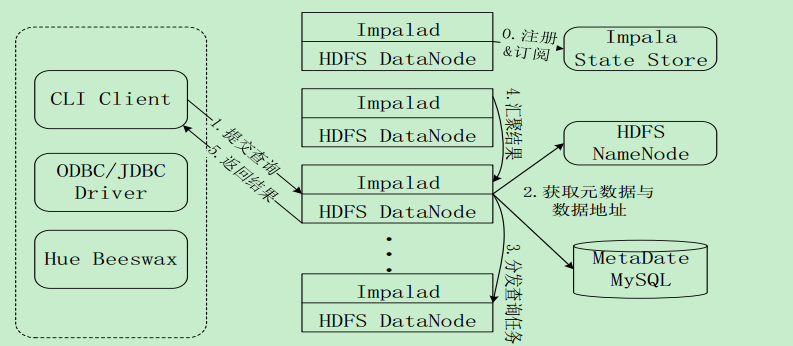
• 第0步, 当用户提交查询前, Impala先创建一个负责协调客户端提交的查询的Impalad进程, 该进程会向Impala State Store提交注册订阅信息,State Store会创建一个statestored进程, statestored进程通过创建多个
线程来处理Impalad的注册订阅信息。• 第1步, 用户通过CLI客户端提交一个查询到impalad进程, Impalad的Query Planner对SQL语句进行解析, 生成解析树;然后, Planner把这个查询的解析树变成若干PlanFragment, 发送到Query Coordinator
• 第2步, Coordinator通过从MySQL元数据库中获取元数据, 从HDFS的名称节点中获取数据地址, 以得到存储这个查询相关数据的所有数据节点。
• 第3步, Coordinator初始化相应impalad上的任务执行, 即把查询任务分配给所有存储这个查询相关数据的数据节点。
• 第4步, Query Executor通过流式交换中间输出, 并由Query Coordinator汇聚来自各个impalad的结果。
• 第5步, Coordinator把汇总后的结果返回给CLI客户端
Impala与Hive的比较
Hive与Impala的不同点总结如下:
Hive适合于长时间的批处理查询分析, 而Impala适合于实时交互式SQL查询
Hive依赖于MapReduce计算框架, Impala把执行计划表现为一棵完整的执行计划树,直接分发执行计划到各个Impalad执行查询
Hive在执行过程中, 如果内存放不下所有数据, 则会使用外存, 以保证查询能顺序执行完成, 而Impala在遇到内存放不下数据时, 不会利用外存, 所以Impala目前处理查询时会受到一定的限制
Hive与Impala的相同点总结如下:
Hive与Impala使用相同的存储数据池, 都支持把数据存储于HDFS和HBase中
Hive与Impala使用相同的元数据
Hive与Impala中对SQL的解释处理比较相似, 都是通过词法分析生成执行计划
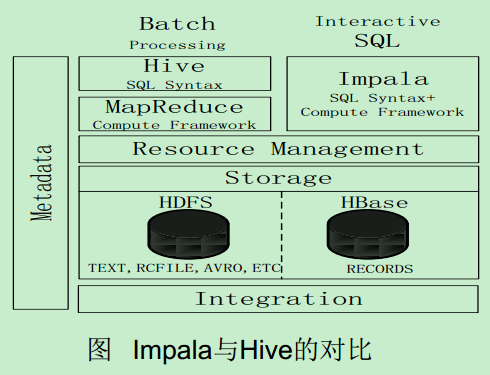
总结
•Impala的目的不在于替换现有的MapReduce工具
•把Hive与Impala配合使用效果最佳
•可以先使用Hive进行数据转换处理,之后再使用Impala在Hive处理后的结果数据集上进行快速的数据分析
Hive编程实践
http://dblab.xmu.edu.cn/post/4331/
`http://dblab.xmu.edu.cn/blog/hive-in-practice
hive配置
Hive有三种运行模式,单机模式、伪分布式模式、分布式模式。均是通过修改hive-site.xml文件实现,如果 hive-site.xml文件不存在,我们可以参考$HIVE_HOME/conf目录下的hive-default.xml.template文件新建。
hive数据类型
基本数据类型:
| 类型 | 描述 | 示例 |
|---|---|---|
| TINYINT | 1个字节(8位)有符号整数 | 1 |
| SMALLINT | 2个字节(16位)有符号整数 | 1 |
| INT | 4个字节(32位)有符号整数 | 1 |
| BIGINT | 8个字节(64位)有符号整数 | 1 |
| FLOAT | 4个字节(32位)单精度浮点数 | 1.0 |
| DOUBLE | 8个字节(64位)双精度浮点数 | 1.0 |
| BOOLEAN | 布尔类型, true/false | true |
| STRING | 字符串,可以指定字符集 | “xmu” |
| TIMESTAMP | 整数、浮点数或者字符串 | 1327882394(Unix新纪元秒) |
| BINARY | 字节数组 | [0,1,0,1,0,1,0,1] |
集合数据类型:
| 类型 | 描述 | 示例 |
|---|---|---|
| ARRAY | 一组有序字段,字段的类型必须相同 | Array(1,2) |
| MAP | 一组无序的键/值对,键的类型必须是原子的,值可以是任何数 据类型,同一个映射的键和值的类型必须相同 | Map(„a‟,1,‟b‟,2) |
| STRUCT | 一组命名的字段,字段类型可以不同 | Struct(„a‟,1,1,0) |
操作
1 | 1. create: 创建数据库、表、视图 |
hive优势
WordCount算法在MapReduce中的编程实现和Hive中编程实现的
主要不同点:
- 采用Hive实现WordCount算法需要编写较少的代码量
• 在MapReduce中, WordCount类由63行Java代码编写而成
• 在Hive中只需要编写7行代码 - 在MapReduce的实现中,需要进行编译生成jar文件来执行算法,而在Hive中不需要
• HiveQL语句的最终实现需要转换为MapReduce任务来执行,这都是由Hive框架自动完成的,用户不需要了解具体实现细节
实验
部署hadoop
http://dblab.xmu.edu.cn/blog/install-hadoop/
安装目录:/usr/local/
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/
core-site.xml 和 hdfs-site.xml
hdfs-site.xml表示节点类型
core-site.xml中,hadoop.tmp.dir 参数表示临时文件目录。
第一次配置后需要对NameNode执行格式化:
1 | ./bin/hdfs namenode -format |
开启守护进程:
1 | ./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格 |
[http://localhost:50070](http://localhost:50070/) 查看信息
部署完了后的使用,测试
要使用 HDFS,首先需要在 HDFS 中创建用户目录:
1 | ./bin/hdfs dfs -mkdir -p /user/hadoop |
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。
1 | ./bin/hdfs dfs -mkdir input |
伪分布式运行 MapReduce 作业:读取的是HDFS中的文件
1 | ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+' |
我们也可以将运行结果取回到本地:
1 | rm -r ./output # 先删除本地的 output 文件夹(如果存在) |
停止hadoop ./sbin/stop-dfs.sh
运行程序时,输出目录不能存在
运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如 output)不能存在,否则会提示错误,因此运行前需要先删除输出目录。在实际开发应用程序时,可考虑在程序中加上如下代码,能在每次运行时自动删除输出目录,避免繁琐的命令行操作:
1 | Configuration conf = new Configuration(); |
测试完毕!
HDFS
<http://dblab.xmu.edu.cn/blog/290-2/>
HBASE
<http://dblab.xmu.edu.cn/blog/install-hbase/>
NoSQL
<http://dblab.xmu.edu.cn/blog/759-2/>
云数据库
<http://dblab.xmu.edu.cn/blog/322/>
MapReduce
<http://dblab.xmu.edu.cn/blog/631-2/>
Hive
<http://dblab.xmu.edu.cn/blog/1080-2/>
英语
replication:
the act of making copies。
[replɪ’keɪʃ(ə)n]
n. 复制;回答;反响
分布式模式:
region
域。
编程问题
idea
添加jar
https://blog.csdn.net/superinzaghi747/article/details/80539095
数学知识
https://segmentfault.com/a/1190000016080294
概念
region概念:
https://www.zhihu.com/question/26872988